A Closer Look at Redis Dictionary Implementation Internals

Note: On October 04, 2017, I published a small article on redis hash table internals. But I think, there are lot more details to cover on redis dictionary topic. Hence as an extension to the previous one, I decided to write this new article which is more comprehensive.
Redis is a very well known in-memory ( persistence can also be enabled for fault tolerance ) data structure store which serves usual key value pairs, List, Set, Sorted Set, HyperLogLog, Geo Spatial structures etc. Redis trades off memory to achieve speed, it performs all client operations in a single thread & usually operations are very fast. Redis is mostly used as a cache or as a storage for ephemerally computed data, so performance is very core to redis.
You can imagine Redis as a big dictionary or hash table ( in redis world, dictionary & hash table are two separate technical words ) which is essentially a key value store. Whether you store string, set, map, sorted set or geo-spatial data to redis, if not all, most of the things somehow gets saved in this big dictionary. This post intends to explain how internally redis dictionary is designed & how they are resized when required.
Components
Redis Database Object
You can have many databases configured in redis. Redis API clients & cli commands interact with this instance. As you can see below, every database object has a member dict *dict which represents the whole key space as a big dictionary in redis. We are mostly interested in exploring this dictionary.
The following image is very helpful & should help you visualize redis dictionary & related structures before we see the code.
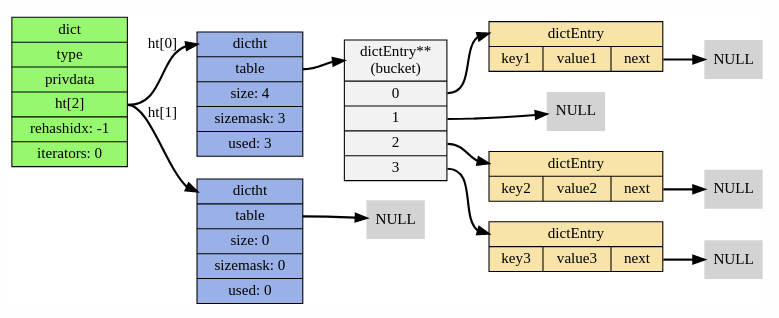
Let’s take a bottom up look into how each structure looks:
dictEntry
A dictionary entry is nothing but a key value pair. The key & value are of type void so that any data type can fit in — better flexibility.
Also dictEntry forms a linked list with each other as you can see in Figure 1.
dictht
This is the hash table implementation in redis. As you can see in Figure 1, dict contains reference to dictht where data actually gets stored.
table: It’s an array of size size . Each table location i.e; table[i] contains a reference to the head of the linked list formed by dictEntry objects as shown in Figure 1. Each table[i] is called a bucket.
Redis uses separate chaining with linked list technique to store multiple entries when hash of their keys collide i.e; they end up in the same bucket. Hence dictEntry objects form a linked list.
So cost of finding an entry = cost of finding the bucket table[i] ( constant cost ) + cost of traversing in the linked list.
size: Allocated size for the table array. size is always in power of 2. The default initial size is 4.
sizemask: It’s used to calculate the hash of a key. sizemask = size - 1.
used: Total number of elements i.e; dictEntry objects currently in the hash table. So it’s nothing but a summation of size of all the bucket linked lists.
dict
type: is an instance of type dictType. dictType defines several utility functions or hooks to manage key & values in the dictionary. See comments in the following code snippet for more details.
privData: Some private data used in hooks. We don’t much need to concern about it.
ht[2]: redis dictionary internally uses hash tables shown in Figure 1 to dump all entries. Typically ht[0] contains all the data in a normal scenario. However, when ht[0] does not have enough space, redis resizes it & ht[1] comes into picture. When resize happens, another process called rehash comes into action. This is the meat of the article, we’ll discuss in later sections.
rehashidx: This is a very important variable in the context of rehashing. rehashidx == -1 means no rehash is in progress currentlyrehashidx ≥ 0 means rehashing of ht[0] is ongoing.
Note: The concept of rehashidx is going to be very important in this article.
iterators: Number of iterators that are currently scanning the redis dictionary to retrieve entries in bulk. There can be multiple such iterators in action simultaneously.
Dictionary Creation & Initialization
This step is quite self explanatory. Each member in dict just get reset to appropriate default state. Note that rehashidx is initialized to -1.
Dictionary Reorganization
Typically hash tables are dynamic in nature, especially when it’s a system like Redis, obviously it has to scale on demand as more and more keys are added or removed.
If you have used Java hash map, you might be already familiar with the concept of load factor: the default java hash map load factor threshold is 0.75 however actual load factor is an implementation specific detail. At any point, when number of elements increases in the map & load factor crosses its threshold, hash map reorganises itself internally i.e; a new underlying map array of double size is created & entries are migrated at once from the older map to the new one. See Java hash map source code for more details.
Redis also conceptually does the same thing, however, it can resize up as well as down to save memory when needed. Redis breaks down the reorganisation operation in two steps:
i. Resize: Creates a new dictht big enough to hold all the entries.
ii. Rehash: A process which migrates entries from the older dictht to the newer one. Resize happens before rehash.
Let’s dive deep into resize operation.
Dictionary Resize
Resize up Condition
Q. When does dictionary scale out?
A. When you add data to any redis data structure through redis-cli or API clients, before adding that to the underlying hash table, redis internally calls the function _dictKeyIndex() which in turn calls the function _dictExpandIfNeeded() to scale out the dictionary if at all required.
Redis maintains couple of global variables to control resizing:
dict_can_resize: redis internally uses this global variable to turn resizing on or off when the system is busy doing some memory heavy operation.
dict_force_resize_ratio: For a hash table ht, it’s defined as ratio of total number of entries to total number of buckets i.e; used / size. Default value is 5. It governs forceful resizing of hash table when it’s absolutely necessary.
Q. What is the load factor in redis hash table?
A. Redis generally maintains a load factor of 1. If used / size is ≥ 1, redis hash table resizes. However, this is not the only decisive factor, let’s understand the code for more details:
Line 33: If a rehash process in progress already, there is no point of resizing the hash table further since before the rehash process starts, resize must have happened already. We’ll see rehash process in the next section.
Q. What is the definition of dictIsRehashing()?
A. It returns true if rehashidx in dict is ≥ 0, else false.
#define dictIsRehashing(d) ((d)->rehashidx != -1)Line 36: ht[0].size == 0 means redis hash table is empty. So, redis creates a new hash table of size DICT_HT_INITIAL_SIZE = 4 & assign that to ht[0].
Line 42–48: This part contains the actual resize logic:
- If total number of elements (
used) is ≥ total number of buckets (size) i.e;used : size ≥ 1:1&dict_can_resizeglobal variable is enabled, the hash tableht[0]can resize. - If the above condition does not apply but
used / size > dict_force_resize_ratio ( = 5), then forcefullyht[0]is resized. Redis hash table can’t tolerate more than this ratio.
Also look at how dictTypeExpandAllowed() is used to decide resizing in line 45. This function is declared in struct dictType in snippet 4. The intention is to check whether allocating more memory is possible for redis — at times, if a huge memory is to be allocated, that operation could make redis unresponsive to clients as huge memory allocation might take some time to complete & redis might need to evict many keys in order to keep its memory footprint under maximum configured server memory. So this method acts as a gate keeper for approving or disapproving such big allocations.
Let’s have a closer look at dictTypeExpandAllowed implementation below:
Line 11: Redis always allocates memory in power of 2. _dictNextPower() just does that job — it allocates memory big enough to hold all the entries.
Line 23–24: Redis uses a special load factor called HASHTABLE_MAX_LOAD_FACTOR = 1.618 in this purpose. If currently used memory ratio ( ht[0].used / ht[0].size ) is less than or equal to HASHTABLE_MAX_LOAD_FACTOR, redis checks if allocating further memory goes beyond configured maximum allowed server memory. If yes, the resize is not allowed.
Line 25–26: However, to guarantee performance, redis still allows memory resize in case the load factor is higher than HASHTABLE_MAX_LOAD_FACTOR . It probably results in a side effect of evicting a lot of keys from the memory.
Q. How to set maximum memory in redis?
A. You can set maxmemory option in redis.conf config file & restart the instance or just run the command from redis-cli: config set maxmemory <value>.
Resize down Condition
Redis can resize down as well when required. Redis expects its underlying hash table to maintain a minimum load factor of 0.1. If hash table size is greater than DICT_HT_INITIAL_SIZE = 4 & load factor is less than 0.1, redis reduces memory footprint by downsizing itself. The function htNeedsResize() implements this logic below.
Line 26: defines function dictResize() which always gets called after htNeedsResize() is called to downsize the dictionary hash table. If redis has turned off dict_can_resize global variable or already a rehash operation is process, then resize won’t happen.
Line 31–34: Since redis is downsizing, it’s appropriate to resize the the dictionary to a size which is the smallest but enough to hold all the current entries. Hence minimum of d->ht[0].used & DICT_HT_INITIAL_SIZE is passed to the dictExpand() function.
Q. Which component takes care of downsizing redis?
A. Redis runs background cron jobs for several house keeping activities. Downsizing memory is one such activity. Also when you delete some elements from redis hash, set or sorted set data structure, redis check if it needs to downsize after deleting them.
Q. What is the frequency of such cron jobs?
A. There is a configuration called hz in redis.conf config file which dictates how many times the server cron jobs run per second usually. The default value of hz is 10 i.e; server cron jobs would run 10 times per second.
According to redis configuration file’s instructions, value of hz can range from 1 to 500, but a value more than 100 is not ideal. Most users should use the default of 10 & bump it up to 100 only in environments where very low latency is required.
Resize Algorithm
Since we have already seen when resize happens, it’s a good time to look at how resize actually happens:
Line 47: Defines the dictExpand() function which is called by _dictExpandIfNeeded() in Snippet 6 to increase the dictionary size & dictResize() in Snippet 8 to decrease the dictionary size. It internally calls the private function called _dictExpand().
Line 5: _dictExpand() accepts size as function parameter which usually but not necessarily represents the current number of entries (i.e; dict->ht[0].used) in the dictionary.
Line 11: If the dictionary is already rehashing, the resize must have already happened. For a proper resize to happen, size should be always greater than current number of elements in the dictionary i.e; dict->ht[0].used .
Line 15: realsize is the new hash table size in power of 2 which is strictly greater than size.
Line 21–31: Allocates the new dictionary of capacity realsize.
Line 35–38: In case the dictionary is already empty, the new hash table is assigned to dict->ht[0]. This condition exists because if you look at the dictExpand() & _dictExpand() functions carefully, it’s easy to realize that they can be used to even allocate a new hash table when the dictionary is completely empty. The functions are pretty generic & they don’t actually explicitly differentiate between resizing & fresh hash table allocation to an empty dictionary.
Line 41: If it’s a resize, the new hash table is allocated to dict->ht[1].
Line 42: rehashidx is set to 0 indicating that the dictionary now needs a rehash process since the resize operation is complete.
Dictionary Rehash
Rehashing is the process of moving buckets of entries from the older hash table ( dict -> ht[0] ) to the new hash table ( dict -> ht[1] ) once the older one gets filled up.
Since Redis is primarily an in-memory data structure store & most of the applications use redis as cache, for a very high scale application, typically redis would contain millions of entries. Given that Redis is known for significantly fast response time for any operation, it would be very difficult to move all of them together to the new hash table. If you move all of them at once, latency would increase resulting in higher response time & possibly blocked client.
In order to tackle this issue, redis very smartly handles the movement. Instead of moving all the entries at once, redis breaks down the operation into a multi-step process & offers the flexibility to move only a group of buckets together in a step. This process is called incremental rehashing.
Since redis handles client queries in a single thread, it takes advantage of such design and manages rehashidx as a global variable. As we have seen already, a successful resize operation sets rehashidx to 0 meaning the rehash process can now can start & can move buckets from ht[0] to ht[1].
Let’s look at the rehash process in details:
Line 11: dictRehash() function accepts a parameter n which represents number of steps. If ht[0].table has no NULL entries i.e; for any i, ht[0].table[i] is non null, n number of buckets would be rehashed otherwise if any ht[0].table[i] is null, there is a possibility that less than n buckets would be rehashed when dictRehash() is called.
Line 12: empty_visits = n * 10 represents maximum how many empty buckets i.e; ht[0].table[i] = null cells redis is going to visit when rehash happens. It’s highly likely that some ht[0].table[i] buckets would be null. In that case, redis does not want to spend a lot of time visiting empty buckets as there is nothing to rehash. So to guarantee responsiveness, n * 10 upper limit is set to empty_visits. If there are more than n * 10 consecutive empty buckets, redis may not even rehash a single bucket in the step.
Line 21–24: In this step, empty visits is decremented, in case it becomes 0, the function simply returns 1 indicating there are still keys left to be migrated. With every empty bucket visit, rehashidx is incremented.
Note: Observe that rehashidx is an index in ht[0].table. So its value ranges from 0 to ht[0].size. In the rehash process, redis moves a bucket from ht[0].table at index rehashidx to some index h in ht[1].table.
Line 25: de points to the head of the linked list at the bucket position rehashidx in ht[0].table.
Line 27–38: The whole bucket mentioned above is going to move to ht[1].table at an appropriate index. The while loop moves the entries in the bucket one by one.
Line 32: Calculates the new index position h in ht[1].table for the bucket to be moved.
Line 35–36: When an entry is moved from ht[0] to ht[1], redis decrements the number of element count in ht[0] & increments the same in ht[1].
Line 39: Once the bucket at index rehashidx in ht[0] is completely moved to ht[1], the bucket at ht[0] is assigned NULL.
Line 40: rehashidx is incremented since the bucket is done with rehashing.
The top while loop at line 15 keeps on iterating till step count n becomes 0 or there is no more element left in ht[0] to rehash. Note that the while loop condition checks ht[0].used not ht[0].size since ht[0].used ≤ ht[0].size, this condition works as a optimization & for redis, any optimization matters :) . This is the reason why redis decrements ht[0].used in line 35.
Line 44–50: Redis checks if the rehash is complete by checking if there is any element left to be moved i.e; ht[0].used == 0. Once complete:
- Line 45: Manually de-allocate memory of
ht[0]for memory management purpose. - Line 46: Reassign
ht[1]toht[0]since it enables redis to operate only on a single tableht[0]for any operation when rehash is not in progress. It just makes redis operations & code easier. - Line 47:
ht[1]is reset i.e;ht[1].tableis set toNULL,ht[1].size,ht[1].sizemaskandht[1].usedare set to0. - Line 48: Assign
rehashidx =-1to indicate no rehash is currently in progress. - Line 49: Returns
0indicating there is no more keys left to be moved.
Q. When does rehash happen exactly?
A. Typically with each dictionary read & write call, redis triggers incremental rehashing with step = 1 ( or n = 1 in snippet 10 ) till the time rehashing is complete. More specifically, following functions defined in redis/src/dict.c file trigger incremental rehashing.
dictAddRaw()
dictGenericDelete()
dictFind()
dictGetRandomKey()The key design choice behind such multi-step rehash is to ensure redis stays responsive to the clients.
Pictorially, the rehash process looks as below:
Before Rehash

During Rehash

After Rehash
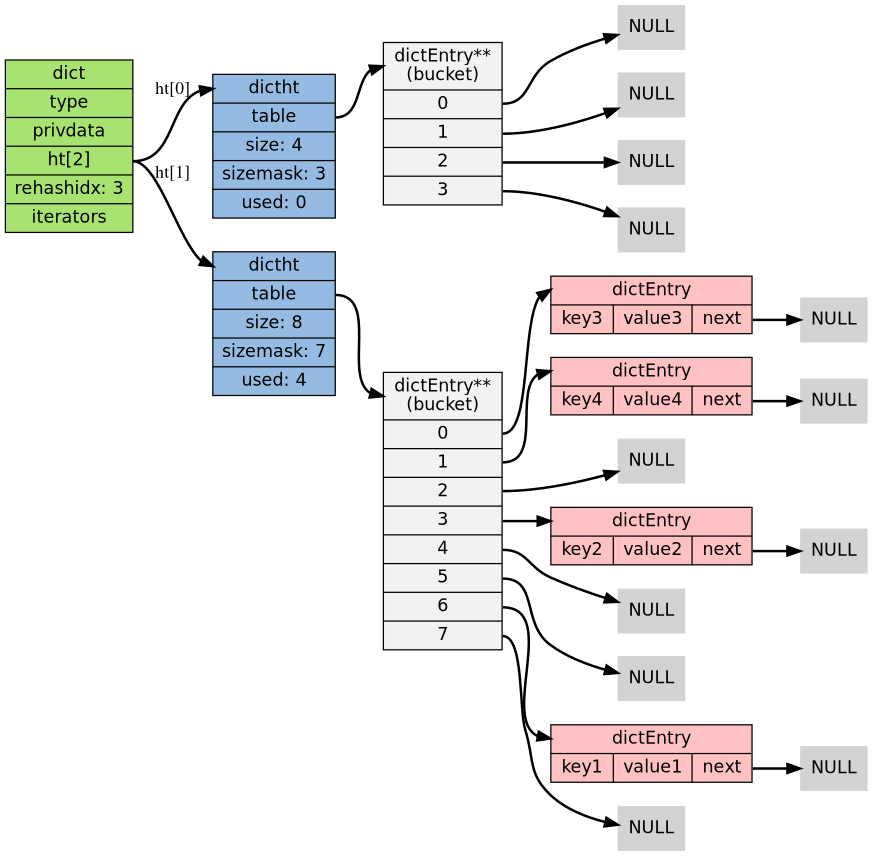
After Dictionary Reassignment

Q. Okay! We now know incremental rehash happens with every dictionary add, get or delete key operation. But what if in some applications, redis sits idle for some time? Shouldn’t redis take advantage of its idle situation & continue the rehashing process?
A. Yes absolutely. Redis handles this scenario as well. Let’s analyze the following code snippet.
Line 9: incrementallyRehash() is called by a background cron job for all redis databases one by one when other memory heavy processes like saving the current database state to disk is not going on & activerehashing flag is turned on in the configuration.
Line 27: Function parameter ms defines the upper bound on the time duration during which the rehash process should continue.
Line 12 & 17: As you can see, redis uses ms = 1 or 1 millisecond duration to time control the rehash process.
Line 33: Redis uses maximum 100 steps in the rehash process. So maximum 100 buckets get rehashed in 1 millisecond duration. However, as it’s very clear that the actual duration could be even more than 1 millisecond if dictRehash(d, 100) takes more time, although typically, it’s between 0 & 1 millisecond.
Since we are now familiar with rehashing concept, let’s discuss two simple use cases where we can see rehashing in action.
Add a key value pair
While inserting string, set, hash etc type data in redis, dictAdd() or dictAddRaw() functions are called internally. There are many other use cases also which call these functions.
Line 17: If the dictionary is in a rehash process, _dictRehashStep() internally calls dictRehash() with n = 1 ( refer to snippet 10 ) i.e; only one rehash step would be performed. This mechanism helps to incrementally rehash the dictionary when add operation is called from anywhere.
Line 21: Checks if the key is already existing in the dictionary. If yes, the key won’t get added. _dictKeyIndex() internally calls _dictExpandIfNeeded() to bump up the dictionary size when necessary. So essentially, every add call internally tries to scale out the dictionary. Refer to snippet 6 for more details on _dictExpandIfNeeded().
Line 28: If rehash is in progress, redis adds the new entry to ht[1], otherwise add to ht[0] only.
Line 29: Allocates memory for the new entry, note that key & value are not assigned to the entry yet.
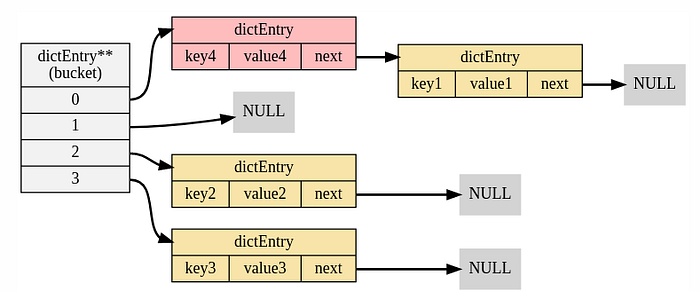
Line 30–31: Observe carefully that the new entry is added at the head of the linked list at the position ht -> table[index]. It’s an optimization based on the assumption that newly added data is accessed more frequently than already existing data — it helps redis to traverse lesser number of list nodes while retrieving the data in future.
Line 32: Number of total entries ( used ) is incremented for the hash table.
Line 35: dictSetKey() assign the key to the new entry.
Line 7: If all good, assign the value val to the new entry.
After adding a new entry ( red coloured entry ), the ht[0] or ht[1] hash table looks like below:
Find a key
Finding a key is a straight forward mechanism.
Line 8: Like dictAddRaw() in snippet 11, redis performs incremental rehashing with 1 step in dictFind() also when a rehash is already in process.
Takeaway: whether it’s a read or write operation, if a rehash is already in progress, redis tries its best to perform a rehash at least with 1 step so that the rehash process completes as soon as possible.
Line 10: When rehash is in process, redis does not know whether ht[0] or ht[1] of the dictionary contains the requested key. So it has to check in both the table in the worst case, hence the for loop. But it’s a small trade-off due to incremental rehashing in the read request path.
Line 13–17: If any matching bucket is found according to the hash of the given key, redis traverses through the linked list to figure out whether the key actually exists. If found, an entry is returned.
Line 18: !dictRehashing() — this step executes after the for loop executes once i.e; ht[0].table is completely traversed. If the given input key is not found in ht[0], there is no point in checking ht[1] if rehashing is not in progress since ht[1] = NULL if rehashing is not in progress. So this step works as a small optimization, again any small optimization is a big gain for :)
Summary
redisDbobject containsdict,dictcontains hash tablesdictht,dicthtis contains an array of linked list ofdictEntry.dict -> ht -> table[i]is called a bucket.- Redis uses separate chaining for hash collision resolution.
- Redis always allocates memory in power of
2. - Default initial hash table size is 4.
dictcontains two hash table instances:ht[0]&ht[1]. In a normal scenario,ht[0]contains all the data &ht[1]isNULL. However, whenever redis needs to resizeht[0],ht[1]becomes non null.- If redis is out of capacity, hash table reorganisation happens & it’s divided into two independent processes: resize & rehash.
- Redis can resize up when load factor i.e;
used / size ≥ 1&dict_can_resizeglobal flag is enabled or forceful resize happens whenused / size ≥ 5. - Redis can resize down when when dictionary size >
DICT_HT_INITIAL_SIZE = 4andused / size < 0.1. - In both the resize option, redis makes sure that the minimum size of the hash table is at least
DICT_HT_INITIAL_SIZE = 4. - Resize down operation is taken care of by background cron jobs. Resize up operation may occur in every dictionary add operation if necessary conditions are fulfilled.
- After resize operation is complete,
dict -> rehashidxis set to0indicating rehash operation can start. rehashidxis an index ondict -> ht[0].rehashidx = -1means no rehash is in progress currently.- Rehash happens after resize is done, it migrates entries from
ht[0]toht[1]gradually. - Rehash process moves around buckets from
dict -> ht[0] -> tableatrehashidxtodict -> ht[1] -> tableat some indexh. - Rehash is a multi-step process, redis usually moves buckets in single step in all dictionary read & write calls.
- A
nstep rehash does not guarantee movement of n buckets since there could be empty buckets inht[0]. Redis puts an upper limit ofn * 10iterations on empty buckets. - Once rehash process completes movement of buckets from
dict -> ht[0]todict -> ht[1],ht[1]is assigned toht[0],ht[1]is reset to default &rehashidxis set to-1indicating that no rehash process is currently in progress. - Rehashing in multiple steps ensures that redis is responsive since moving millions of entries from one hash table to another at once could block redis for long time.
- While adding any entry to the dictionary, if rehashing is already going on, redis adds the new entry to
dict -> ht[1]. Redis adds the new entry to the head of the linked list at the bucket position so that finding this entry in future becomes faster. - In find key or read call, redis searches the key in both
ht[0]&ht[1]if rehashing is going on. This is a trade off due to incremental rehashing.
Redis dictionary has a lot of other methods. I would highly encourage you to checkout redis github repository & skim through the source code if you are curious like me :P. I wanted to give enough details so that the community knows how redis dictionary internal looks like & gets familiar with the core of the code base.
If you have reached here, congrats! you must have liked this article. Please give multiple claps & share on LinkedIn, Twitter so that the community benefits from it.
Have any feedback in mind? Please leave a comment.

