Building Resilient Platform, Part 2
In Part 1 we looked at adding resiliency to our application by following circuit breaker pattern popularized by Netflix hystrix framework and adding a circuit breaker into our service client pipeline, which made our application more resilient to the downstream service problems. But as we said the problem still remains and in this post we are going to fix it.
To reiterate, our architecture looks as follows now:
If we look at this model from service point of view, the application endpoint and hence the whole distributed system still remains unprotected unless one completely controls external traffic; which may be a hard task to do. Not all clients can be ‘nice’ to our application even if they belong to our internal applications.
For example, we found that some developers can disable circuit breaker or delay its occurrence by tuning circuit breaker parameters. Another example is when a cluster of applications gets restarted at the same time due to some big downtime event; which may cause a lot of pressure on downstream services and slow down or block the recovery of the entire system. We should also account for silent bugs that can occur when all the circumstantial factors happen at the same time triggering an unexpected behavior of the clients.
There are sub-optimal measures available like a rate limiter, which involves manual work, after the fact, reacting by OPS engineers to the failure events after they have already happened and the usual action is to disable unimportant traffic like bot traffic, divert traffic to other data centers and restart the boxes trying to blindly fix the problem; which shows up as connections stacking on LB side.
Even just by looking at the diagram above, I get an uneasy feeling that something is missing on our diagram. So, let’s add a missing piece.
The idea
Why not use the same circuit breaker pattern on incoming traffic at service endpoints automatically guarding them from rogue or uncontrolled client calls from upstream?
By doing so we not only get a basic resiliency to our service incoming traffic pipeline similar to the use of circuit breaker in the service client pipelines, but more importantly this gives us a control on how to react to different situations with an incoming traffic based on its type via hystrix patterns (fallback, fail fast, fail silent).
This addition makes the Circuit Breaker pattern complete.
Our solution
We here at eBay are committed to give back to the open source community as it brought us a great deal of success in making our system more developer friendly, standard, clean and reliable. In fact, the latest wave of innovation this article describes has been brought by appearance of very good implementation of hystrix framework in node.js world — hystrixjs module that triggered a wave of innovation in resiliency of our platform based on hystrix patterns and helped us to look from a different angle on our open source service pipeline framework.
Even though the solution presented here is based on node.js environment, the same solutions with slight modifications can be applied in any other language where hystrix implementation is available.
So far the immediate goals for our node.js stack is to address two major cases:
- Shedding load when the system becomes too busy.
- Reacting to unexpected traffic.
Handling busy systems
It is always good to prevent overwhelming of the system by too much traffic sooner than later. There are various causes for this situation. It can be due to DDoS attack or when traffic is diverted from other data center without regard to the capacity of the target data center and things like that.
In our case we better do it before CPU gets saturated and makes the system slow not just to external clients, but for internal tasks that must be taken to mitigate the situation as well as report about the incident.
So, how do we do it?
In node.js the standard way to detect the system busy state is to measure latency of the event loop, a delay between expected and actual timer event, which reflects how busy the event loop is.
There are a few popular modules available in node.js repository like toobusy-js but from our experience they are unreliable and can frequently misfire causing unnecessary traffic loss due traffic shedding. An unpredicted behavior of the application as well as its memory profile where GC can sometimes take more time to cleanup than expected can lead to false positives. What is needed is a way to observe the situations as it develops over time and decide if this is a true busy case or other transient state. Hystrix does exactly what we need with observation and provides a rich set of parameters to tune.
By coupling too-busy module with hystrixjs module we are getting more reliable way of detecting when the system becomes too busy. As a bonus we also get its metrics exposed to the hystrix dashboard.
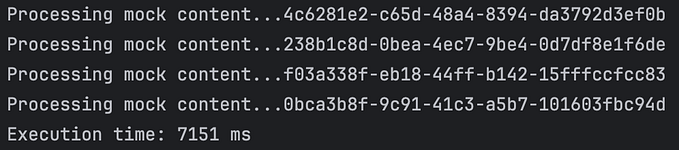
Here’s what we got by running stress tests on one of our test apps that uses our express-hystrix and hystrix-too-busy modules on incoming traffic
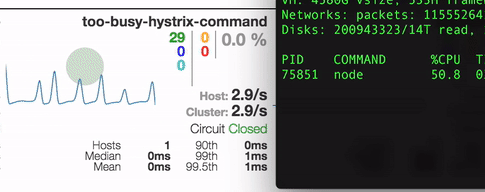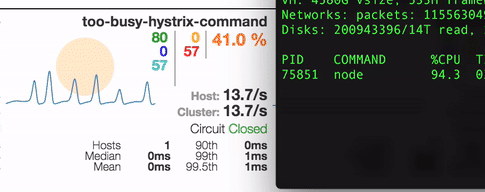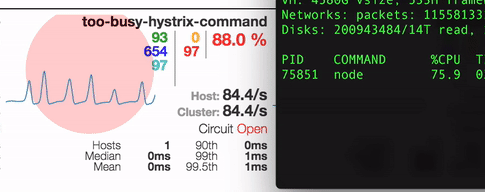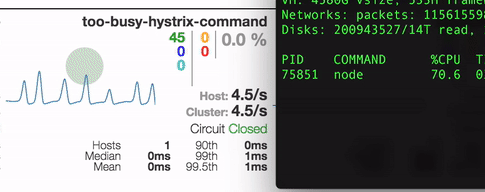
The setup is pretty simple
Now, if you run it, you can see the metrics in the dashboard at this location and generate some load using this url (http://localhost:8000/hello). The dashboard will have a generic too-busy-hystrix-command and a /hello command that can be configured to react to too-busy errors.
Reacting to unexpected traffic
Now, let’s look at the second major external factor, the unexpected traffic; which is any traffic or the volume not expected by the target application, for example, it can be unexpected increase of traffic due to security scanner traffic or a wrong setup of LB. The strategies to fallback will depend on the type of the traffic and application specific requirements.
If we prevent wrong/unknown traffic going through our service/web request pipeline, we could preserve CPU resources that can be used for the ‘good’ requests, hence increasing capacity of the whole system. Another example is when application has a bug that results in a constant generation of 404 responses, we may decide to shed it and report the incident to the application owners.
Can we do better? Absolutely!
Both of the above measures (too busy and unexpected traffic) can be improved even more by understanding the type of traffic like internal vs external, bot traffic vs real traffic, security scanner traffic at platform level. By assigning priorities to the traffic we can control shedding.
The application itself can use a priority system in regard to its routes, for example the money generating flows can get a higher priority than the less important routes. The priorities are controlled by setting more aggressive threshold to open circuit for unimportant commands.
Here’s a few examples on what we can do with it:
- Recognize type of traffic and assign priorities:
- Operations/health checks (generate special signals that can start re-routing of traffic)
- Bot traffic, assign low priority to shed it sooner.
- Web traffic, assign high priority to delay traffic shedding.
- External/Internal, where internal traffic can come from security scanner which we can automatically shed at times of stress.
- Bad/Unknown requests handling can give an option to application team to prevent unexpected requests decreasing application capacity. - Automatic Rate Limiter using above factors and trigger point
- Based on CPU usage (TOO-BUSY in node.js)
- Based on request wait time in queue (in java) - Automatically divert traffic to other data center
- Automatically restart the worker or the whole app.
- DDoS blocker
- Runtime metrics available with hystrix module by default
- Automatic reporting to central logging system of the emergency state of the app/service
This functionality is provided by our express-hystrix module that allows to plug different behavior based on application requirements. By default it provides too-busy and connection error reaction to an express application request flow. One can implement more, for example, marking 5xx requests as bad or handling bot traffic.
The below example demonstrates marking all 404 request as invalid and effectively removing them from request pipeline as long as one puts hystrix handler at the very beginning of the pipe.
Once you start the above application, you can open dashboard and then try loading valid and invalid routes multiple times and see what will happen.
All right, that’s all for Today. Please feel free to use the above mentioned modules and let us know what you think.
In Part 3 we will review different strategies for falling back when the circuit is open, implement smarter hystrix commands to handle different traffic, squeeze more juice out of hystrix.