
Machine Learning. Explanation of Collaborative Filtering vs Content Based Filtering.
Recommender systems help users select similar items when something is being chosen online. Companies such as Netflix or Amazon, would suggest users different movies that might interest them and are worth watching. Yelp is using similar algorithms to suggest different restaurants and services. These types of algorithms lead to service improvement and customers satisfaction. Exploring and evaluating recommender systems for Yelp to recommend the best sushi place to user by creating profiles for users and sushi places based on discovered ratings and restaurant features. The method is based on content and collaborative filtering approach that captures correlation between user preferences and item features.
Introduction
Mass customization is becoming more popular than ever. Current recommendation systems such as content-based filtering and collaborative filtering use different information sources to make recommendations [1]. Content-based filtering, makes recommendations based on user preferences for product features. Collaborative filtering mimics user-to-user recommendations. It predicts users preferences as a linear, weighted combination of other user preferences.
Both methods have limitations. Content-based filtering can recommend a new item, but needs more data of user preference in order to incorporate best match. Similar, collaborative filtering needs large dataset with active users who rated a product before in order to make accurate predictions. Combination of these different recommendation systems called hybrid systems [2].
They can mix the features of the item itself and the preferences of other users.
Research Question
Question as an example being explored “what is the best sushi place to be recommended to user?”. Finding users that are related to user likes and the best recommender system improves user experience by recommending best matched products, reducing search times and frustration.
Proposed Solution
Two basic recommender systems are being used for recommendations. Content-based filtering and Collaborative filtering.
First method, Content-based filtering. It relies on similarities between features of the items. It recommends items to a customer based on previously rated highest items by the same customer. List of features about these items needs to be generated.
- Each item will have an item profile
- A table structure will list these properties
- Comparing what and how many features match and collect scores
- Recommend highest scored item
- Code will be based on an algorithm, by given some item, the most similar item will be found
- Best scoring match will be provided to the user
- This method relies on item features only, and not the user preferences.
Second method, Collaborative filtering. It relies on how other users responded to these same items. It doesn’t rely of features of the item, but the preferences from other users. Similar users survey needs to be done.
- Users will have a table with different rated items of what they choose or liked
- Based on the similarities, prediction can be make of what the user might like, based on what similar users did.
- The list will be filtered and matched to users who used the same items for comparison and recommendations
- Everything will be summed up and highest score will be recommended
- Code will be created based on an algorithm, by given a user x, recommend an item that x might like
- Item with the highest score will be recommended
Problem with this method is that you need to have a data to make recommendations. More data you have, better recommendations will be.
Data Processing
Dataset is being extracted from Yelp dataset challenge online at https://www.yelp.com/dataset/download. It’s being filtered by user ratings of sushi places and demanded features around Los Angeles area. Users information and ratings are being collected.
4 user profiles and 5 item profiles are being constructed as an example, based on top 5 sushi places in Los Angeles. Sushi A, Sushi B, Sushi C, Sushi D and Sushi E.
Content based filtering table was based on features of meaningful words in the sushi places. TF-IDF was being used as shown below in the Figure 1.

Collaborative filtering table was based on user ratings of the sushi places as shown in Figure 2 below.
- Alex rated all of the 5 sushi places: Sushi A, Sushi B, Sushi C, Sushi D and Sushi E
- Bertha rated 3 sushi places: Sushi B, Sushi C and Sushi E
- Colin only rated 2 sushi places: Sushi C and Sushi E
- Ethan rated 1 sushi place: Sushi E

Evaluation Methods and Results
Content-based evaluation item profile can be seen as vector. Measured 0 or 1, depends on YES or NO of containing a feature inside that item.
Profile item was created by evaluating the item and finding meaningful words.
To pick important words, TF-IDF method was used. It looked for featured and important words to user in the sushi places. TFij stands for feature x in document y is number of times the feature x appears in document y divided by number of times that same feature appeared in a document. For example word salmon, appeared in a document 5 times. But in the other document it appeared 23 times. Then, the TFij = 5/23. The documents needed to be normalized in order to compare longer documents. The more times word appear, more important it is.
However, some words are more important that the others. For example little words “the” might appear a thousand times, but it’s not important at all. That’s where the document frequency comes in.
- nx= number of documents that mention term x
- N = total number of documents
- IDFx (inversed document frequency for the word x) = log (N/nx)
More common the term, larger the x and lower IDF. It gives lower rate to common words and higher score to rare. Then, a given document was being calculated term in scores.
TF-IDF score: wxy (word x in y) = TFxy (IDFx)
So given document you computer TF-IDF scores for every term in a document, and pick highest score and that would be the document profile.
The formula for the TF-IDF score is:

Featured words were: Salmon, Tuna, Eel, Crab and Ramen as shown in Figure 3 below.

Boolean values were being used to build the table below. Similarities were being compared between 5 sushi places, to see how many matches. It showed that there 4 matches between Sushi A and Sushi B, 5 matches between Sushi A and Sushi C, 4 matches between Sushi A and Sushi D and 3 matches between Sushi A and Sushi E.
The Best match for Sushi A is Sushi C.
Below is a coded data structure for that called sushi:
typedef struct { bool Salmon; bool Tuna; bool Eel; bool Crab; bool Ramen; } sushi;
To compute if the items similar or not, and what their score is, a set of pseudocode to generate the same function is:
Given a sushi s1, find the most popular sushi
Set BestScore to some minimum value (0)
For each other sushi s2
Set MatchScore = 0
For each feature
Compare s1 and s2 on that feature
If they match, increment MatchScore
If MatchScore > BestScore
then BestMatch = s2 and
BestScore = MatchScore
Return BestMatch
Next, Collaborative filtering method was being used to create user profiles. It’s was being generated from other users preferences. Users with different types of sushi places were scored.
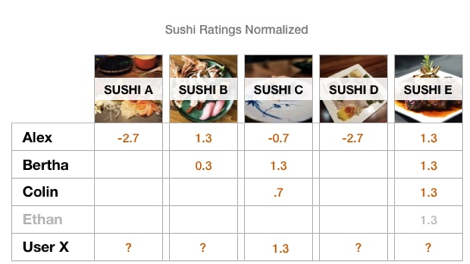
As was shown in Figure 2 above, Sushi A rated 1. Sushi B rated 5,4. Sushi C rated 3,5,2, Sushi D rated 1, and Sushi E rated 5,5,5,5. Just by looking at the number it seemed that all users have differences in scores except Sushi E. Similarities needed to be defined.
Centered Cosine or Pearson Correlation method was used. It captures intuition better. The way it works is by finding row mean.
To recommend the best next sushi place to try, ratings need to be normalized by subtracting user’s rating mean (3.7) from the user ratings.
- 41 (sum of scores)/11(number of ratings) = 3.7
- Sushi A profile weight = -2.7/1 = -2.7
- Sushi B profile weight = 1.6/2 = .8
- Sushi C profile weight = 1.3/3 = .43
- Sushi D profile weight = -2.7/1 = -2.7
- Sushi E profile weight = 5.2/4 = 1.3
Results — user didn’t like Sushi A and Sushi D.
Some users didn’t rate all sushi places and the challenge was to decide on how to deal with these missing values. When we add a user who only rated Sushi C, the next sushi match that is recommended will be Sushi E, since it has the highest rating score. Ethan scores are being eliminated for comparison, since he didn’t rate Sushi C before, as shown in Figure 4 below.
Below is a coded data structure for that called user. It shows features of which sushi places user liked:
typedef struct {bool LikedSushiA; bool LikedSushiB; bool LikedSushiC; bool LikedSushiD; bool LikedSushiE; } user;
Additionally to compute what user x might like, a set of pseudocode can be generated as:
Given a user x, recommend a sushi that x might like
For all sushi s
Set score [s] = 0
For each other user y
If y’s preferences match x’s preferences
increment score[s] for all s that u likes
Find the sushi with the highest score and return it
To make better predictions, almost all the major systems use hybrid recommender systems.
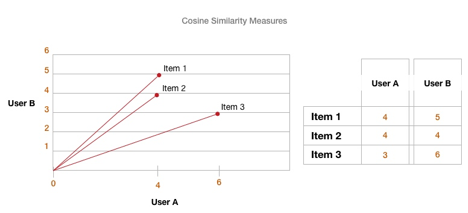
It combines user profiles with item profiles and comparing to figure out what the rating will be for the user and the item.
To estimate the angel, a cosine similarity is being calculated. The smaller angel, the more similar the item is. The cosine similarity is being calculated between the user and items catalog. Then, the highest cosine score is being recommended to the user.
Conclusion
Content-based filtering outperforms user collaborative filtering. Items are more similar and make more sense than users similarities.
The experiment showed that if a user liked Sushi Place A before, then the next recommendation should be Sushi C, since it scored the highest.
However, if the recommendation based on other users preferences based on similarities, then it showed that users didn’t like Sushi A and Sushi D. Based on their weighed scores, it showed that Sushi E would be the best recommendation.
Good thing about content based approach that you don’t need data about other users in order to make recommendations.
Problem with collaborative filtering is that when a unique user has a unique taste, there might not be similar matches of other users. Meanwhile, the content based approach can be build based on user and item profiles. Items can be recommended based on previous choices.
However, if a user never rated an item, it won’t be in the recommendations list.
The best approach would be to use a combination of different approaches. Mix of collaborative and content based filtering. Some of it will depend on preferences of the users and some on item features.
References
[1] Ansari, A. (n.d.). Internet Recommendation Systems. Retrieved August/September, 2000, from https://www0.gsb.columbia.edu/mygsb/faculty/research/pubfiles/385/Internet Recommendation Systems.pdf
[2] Shi, C. (2017, June 27). A Hybrid Recommender with Yelp Challenge. Retrieved from https://nycdatascience.com/blog/student-works/yelp-recommender-part-1/
[3] Maryam Khademi, M. (n.d.). Predicting a Business’ Star in Yelp from Its Reviews’ Text Alone. Retrieved from https://arxiv.org/pdf/1401.0864.pdf
[4] Jiaotong, X. (2013, October 1). Recommendation via user’s personality and social contextual. Retrieved from https://www.researchgate.net/profile/Xueming_Qian/publication/262328219_Recommendation_via_user's_personality_and_social_contextual/links/55472daa0cf234bdb21dbc85.pdf
[5] Xiaozhong, L., & Turtle, H. (2013, June 12). Real‐time user interest modeling for real‐time ranking. Retrieved from https://onlinelibrary.wiley.com/doi/abs/10.1002/asi.22862

