Notes on “How Browsers Work” 💻
My notes on Tali Garsiel’s wonderful research from 2011 that still has relevance today
DISCLAIMER: All of the following is based-off/taken from this research by Tali Garsiel.
The vast majority of this article consists of summaries of her content, but I believe I’ve refactored enough parts/added enough content such that my notes are significantly different from her original article — and that it could provide a different experience for readers. I believe this article has a substantial raison d’être.
Before anything else, I give much respect and praise to Tali for her amazing efforts.
Let’s dive in!
Table of Contents
- Structure of a Web Browser
- The Rendering Engine
- Parsing: DOM Tree & CSSOM Tree
- Render Tree
- Layout
- Painting
- Dynamic Changes
- The Rendering Engine’s Threads
- CSS Visual Model
1. Structure of a Web Browser
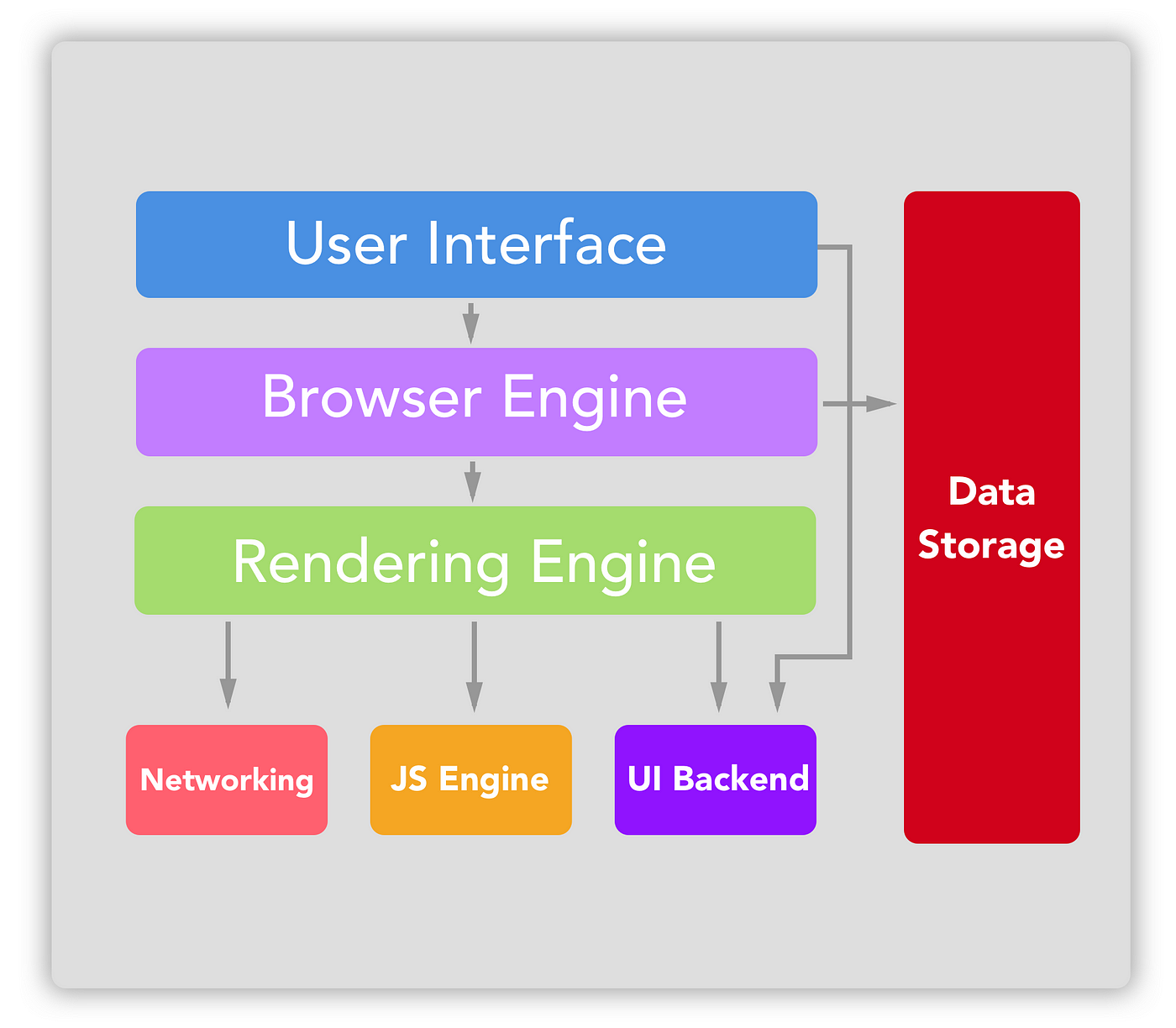
At a high level, all (non-headless) web browsers are composed of 7 parts.
In implementations, some of these parts can be combined. For example, Mozilla’s “Gecko” engine combines the Browser Engine and the Rendering Engine. However, Gecko’s functionality can still be divided into the roles of a Browser Engine and a Rendering Engine.
Here are the 7 abstract parts of web browsers:
- User Interface
- Browser Engine
- Rendering Engine
- Networking Component
- JavaScript Engine
- UI Backend
- Data Storage
User Interface
- Everything you see except the web page itself.
- Address Bar
- Back/Forward Button
- Bookmark Menu
- Close, Minimize, Full-screen buttons
- Refresh Button
- Tab Management Area
Browser Engine
- Provides a high-level interface for querying and manipulating the Rendering Engine.
- Acts as a middleman between the User Interface and the Rendering Engine.
- Communicates with the Data Storage component.
- This is sometimes combined with the Rendering Engine, such as in Firefox’s “Gecko” engine.
Rendering Engine
- Displays requested content.
- The vast majority of the time, this is HTML + CSS. But not always. With the help of plugins, the rendering engine can also display other media:
- PDFs
- XML documents
Networking Component
- Responsible for handling network tasks:
- HTTP Requests
- WebSockets (Duplex connections over TCP)
- WebRTC (Uses Real-Time Transport Protocol, which uses UDP) - Exposes a platform-agnostic interface, but binds to platform-specific functions.
JavaScript Engine
- Executes JavaScript.
- Traditionally, a runtime interpreter was used to execute JavaScript. Now, all major browsers use JS Engines that utilize Just-in-Time Compilation.
UI Backend
- Used for drawing everything in the browser, both in the User Interface and in the Rendering Engine.
- Binds to platform-specific functions, but Exposes a platform-agnostic interface.
Data Storage
- Used for persisting data locally.
- Used for:
- HTTP Cookies
- Browser Caching
- Web APIs such as Web Storage and IndexedDB
2. The Rendering Engine
- Overview of the Rendering Process
- WebKit’s Rendering Process
The Rendering Engine is of particular interest to me. Thus, I will focus on it for the remainder of this article.
The Rendering Engine renders content/displays it to the screen.
The Rendering Engine can render many types of media through the use of plug-ins or extensions including: HTML+CSS, PDFs, and XML documents.
However, the obvious, primary application is rendering HTML+CSS, so that is what we will focus on.
OVERVIEW OF THE RENDERING PROCESS
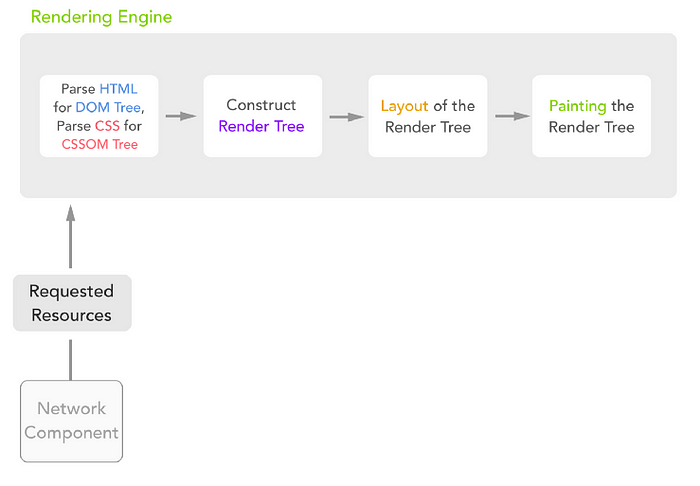
First, the Rendering Engine retrieves the Requested Resources from the Network Component. Then:
- HTML is parsed to create the DOM Tree.
CSS (both in external stylesheets and<style>tags) is parsed to create the CSSOM Tree. - DOM Tree + CSSOM Tree= Render Tree.
The Render Tree is a tree of styled DOM nodes.
It is a tree of boxes complete with their cosmetic characteristics: color, dimensions, etc. - Each render-tree node is laid-out.
Each render-tree node learns its exact positional coordinates on the screen. - The Render Tree is traversed. Each node is painted onto the screen using the UI Backend.
Qualification*
This is a simplification. The image and list imply that this all happens in a single, gigantic pass.
That’s wrong.
The rendering process is a gradual, asynchronous process.
For a better user experience, the rendering engine will attempt to render content ASAP.
That means that it won’t wait until all the requested resources return from the networking component to begin painting render-tree nodes.
It won’t even wait until all the HTML is parsed.
It will parse & render the HTML/CSS in chunks.
Rather than:
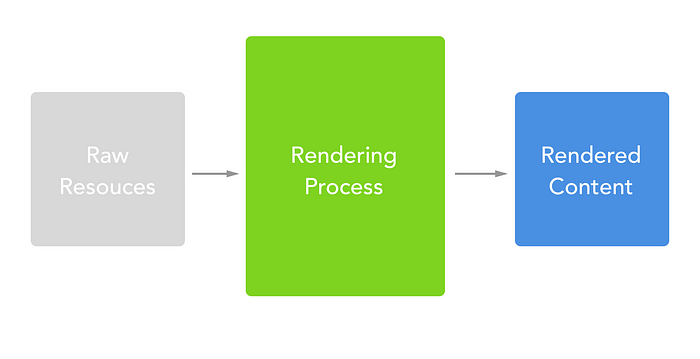
You should think of the Rendering Process more like:
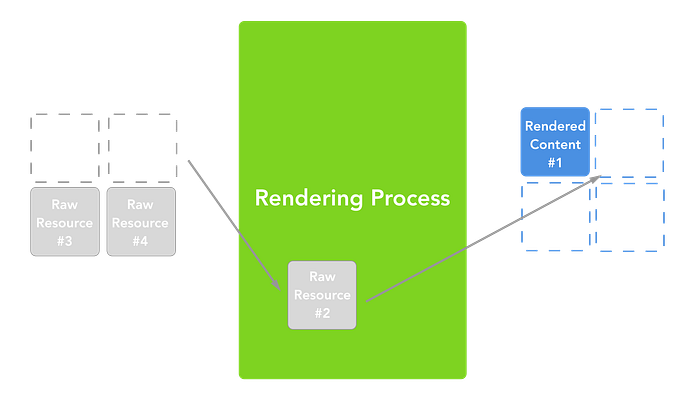
To reiterate:
Rendering happens before all content has been completely parsed.
Content is parsed & rendered in chunks.
A single, gigantic parse & render cycle over a monolith of content is NOT what happens.
WEBKIT’S RENDERING PROCESS
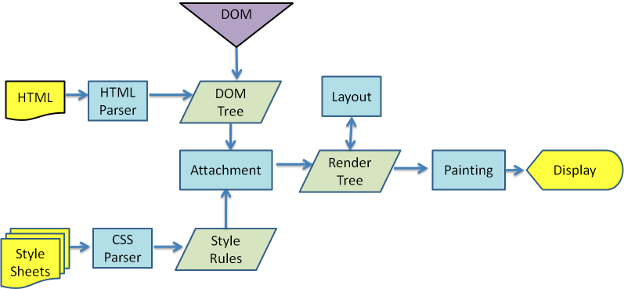
WebKit is the rendering engine used in Safari. Google and Opera use the Blink rendering engine, which is a fork of WebKit.
This is a detailed overview of WebKit’s rendering process. You can see that it mostly matches my diagram from above, with some differences that I don’t quite understand yet.
3. Parsing: DOM Tree & CSSOM Tree
- General Parsing
- HTML Parsing
- CSS Parsing
- Parsing Scripts and Stylesheets

This section corresponds to Step 1 of The Rendering Process.
Before we discuss HTML parsing and CSS parsing, let’s discuss General Parsing first.
GENERAL PARSING
- Grammars
- Lexical Analysis
- Syntactic Analysis
- Translation
- Formally Defining Lexicons and Syntaxes
- Generating Lexers & Parsers Automatically
- Recap of General Parsing
In this context, “parse” means “transform raw text into a parse tree”.
Let us examine a non-programming example: 2 + 3 — 1.
Consider 2 + 3 — 1 as a string: "2 + 3 — 1".
This is what the result of parsing it might look like:
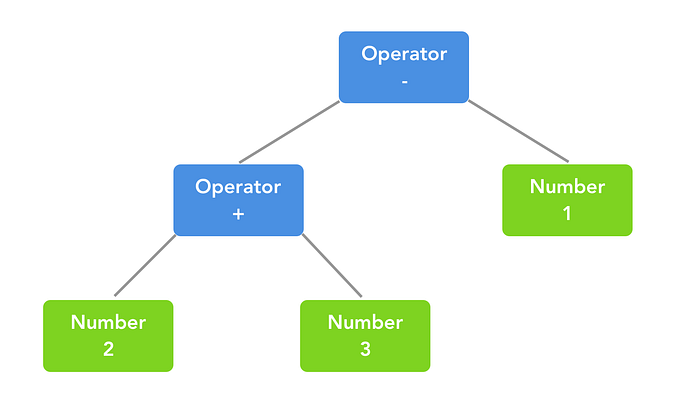
Without being told what parsing is, you probably have a good intuition of what it is, based on this image.
We started with a raw string, and ended up with a parse tree: a data structure that accurately reflects the syntax of the string,
Grammars
Parsing a simple mathematical expression is relatively straightforward.
As you can imagine, not all languages are this easy to parse.
Different languages yield different parsing difficulties.
For example, parsing a general human language such as English is much, much more difficult.
This is because different languages have different grammars.
What is a grammar?
A grammar is a precise description of a formal language. I.e., it describes what possible sequence of symbols/string constitute valid words or sentences in that language, but doesn’t describe their semantics. — (Vinay Bharadwaj in linked Quora Post)
The difficulty of parsing a language arises from the complexity of its grammar.
There are 4 distinct categories of grammars, outlined in the Chomsky Hierarchy:
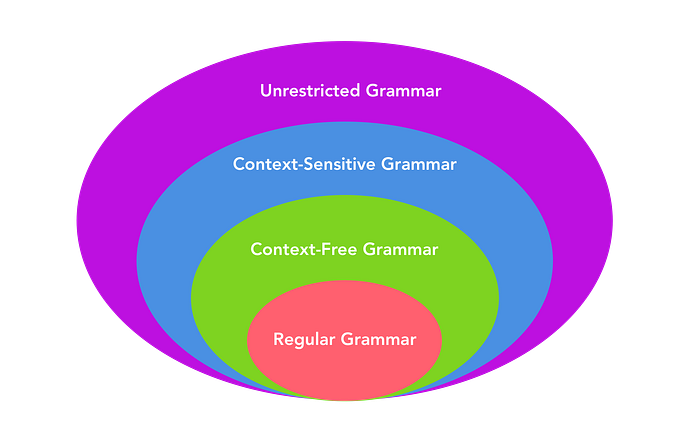
Ordered in descending order — simplest grammar to most complex:
- Regular Grammar
- Context-Free Grammar
- Context-Sensitive Grammar
- Unrestricted Grammar
I won’t deeply discuss the meaning of each grammar. But it’s worth nothing that regular languages (languages expressed by a regular grammar) can be parsed using regular expressions — the things we know as RegEx in software development.
Knowledge of grammars will be necessary for the next section: Lexical Analysis and Syntactic Analysis.
Lexical Analysis
Lexical analysis, otherwise known as tokenization, is the process of breaking down raw input into atomic structures/tokens.
The meaning of “token” depends on the language’s lexicon/vocabulary/body of valid words.
In English, tokens would be words in a dictionary: “cat”, “dog”, “incidence”, “brumous”, etc.
For example, consider the phrase “The quick brown fox jumps”
If we were to lexically analyze this phrase, we would obtain the following tokens:
- “The”
- “quick”
- “brown”
- “fox”
- “jumps”
To recap, lexical analysis is breaking down raw input into tokens according to the language’s lexicon.
In parsing, the machine that performs lexical analysis is known as a lexer.
Syntactic Analysis
Syntactic Analysis is the validation of a sequence of tokens. I.e. confirming that a sequence of tokens forms a valid expression.
Consider the phrase: “I brown quickly Eiffel Tower”.
If we were to syntactically analyze this phrase, we would conclude that it’s invalid. This does not conform to the syntax of standard English.
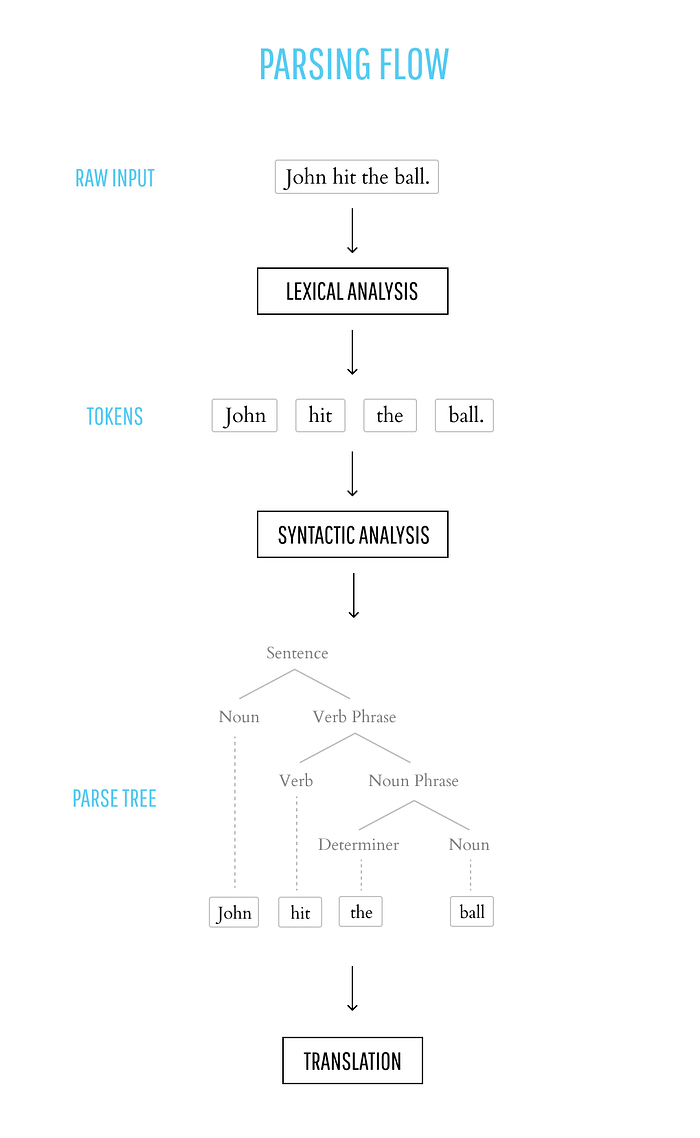
Consider the phrase: “John hit the ball.”
If we were to syntactically analyze this phrase, we would conclude that it’s valid. This does conform to the syntax of standard English.
An important note: Syntactic Analysis is unconcerned with semantics.
Consider the exemplary phrase: “Colorless green ideas sleep furiously”.
This is syntactically correct, but is semantically incorrect because it has no logical meaning.
In parsing, the machine that performs syntactic analysis is known as a parser*.
The output syntactic analysis is a parse tree, a tree whose structure represents the syntactic structure of the input.
The parse tree of “John hit the ball” might look like:

After the parse tree is created, we’re at the home stretch. There’s only 1 step left: Translation.
Translation
Once you have your parse tree, you have all the information you need. Now you actually have to do something with it.
Translation is just a general term for this. In a software context, it usually means compilation/transpilation/interpretation.
Formally Defining Lexicons and Syntaxes
Formal lexicons are defined by regular expressions. For instance, consider identifiers in JavaScript. They are part of the lexicon.
Here is the regular expression for identifiers in JavaScript, given by Mathias Bynens on StackOverflow. It’s insanely long, but does capture all the valid possibilities for an identifier.
Formal syntaxes are USUALLY-BUT-NOT-ALWAYS defined by a context-free grammar. I don’t really want discuss what a context-free grammar is, so here’s the wikipedia article on it.
Just know that it’s more complex than a regular grammar, but still easily manageable.
Generating Lexers & Parsers Automatically
Lexers and parsers are typically not written from scratch. That would be very difficult. There are tools for generating lexers & parsers simply by feeding them a language’s lexicon and syntax respectively.
WebKit uses 2 such tools: Flex and Bison.
Flex (fast lexer) generates lexers.
It consumes RegExps detailing a lexicon.
Bison generates parsers.
It consumes a syntax described in Backus-Naur form.
Recap of General Parsing
We now have a basic understanding of parsing in the general sense.
To recap:
Lexers and parsers are typically not written by hand. Tools such as Flex and Bison are used to generate lexers and parsers respectively.
We are now ready to discuss HTML parsing specifically.
HTML PARSING
- Lexicon
- Syntax
- DOM Tree
- Example: Error Tolerance
- DTD: Document Type Declaration
Tali Garsiel discusses the (absurdly many) intricacies of HTML parsing much more than I will. For more information, read her original writing on it. I don’t really have the bandwidth to provide that much depth, and she really does it better than I ever could, so I encourage you to check out her work.
Lexicon
(Spec. on HTML5 lexing by the WHATWG)
HTML’s lexicon consists of 6 tokens:
DOCTYPEStart TagEnd TagCommentCharacterEnd-of-file
When an HTML document is being lexed, the lexer reads characters from the document piece-by-piece and uses a finite-state machine to recognize when a full token has been received.
Syntax
This is where the complexity of parsing HTML is.
TL;DR: HTML5’s extremely forgiving nature requires a context-sensitive grammar. If HTML5 had no error-tolerance at all, then a context-free grammar could be used.
I will expand on this in an upcoming section.
DOM Tree
The parse tree of HTML is not exactly the DOM tree. The DOM tree is an HTML parse tree that is reformatted for consumption in the browser.
Keep that in mind when examining the DOM tree below.
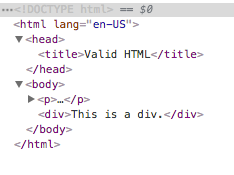
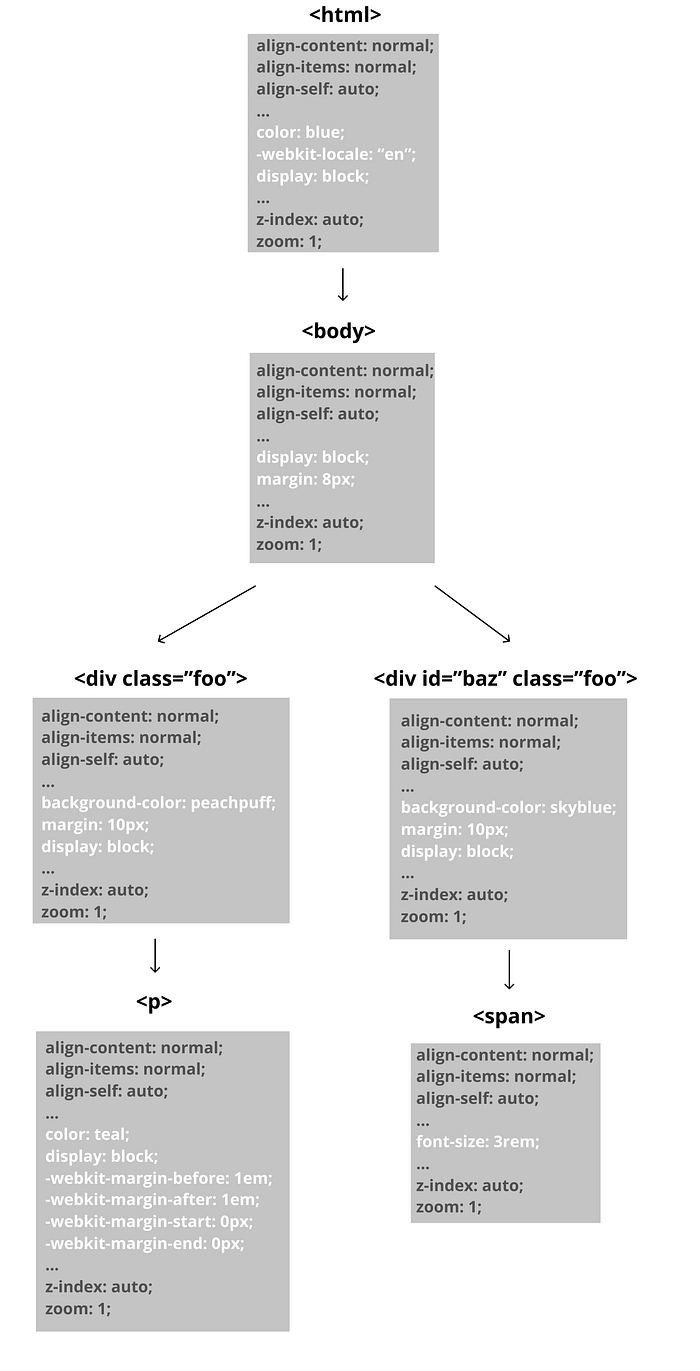
Consider the following HTML:
Its DOM Tree would be:

(There are actually several more Text nodes. I didn’t include them b/c they just hold the LFs)
Example: Error Tolerance
These 2 examples render nearly the same:
The 1st snippet is perfectly valid HTML.
The 2nd snippet has several “errors”:
- No DOCTYPE
- No closing
</html> - No
<body></body> - No closing tags on
<p>,<span>,<div> langattribute has mixed-casing- attribute-value
EN-USis not wrapped in double-quotes - spaces surrounding the
=inlAnG = EN-US
Yet, the resultant markup is nearly identical:
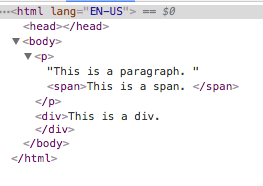
The only difference is that the valid markup includes the <!DOCTYPE html>, which triggers standards mode.
So you can see that HTML5 is very forgiving. However, this flexibility comes at a cost: the increased grammatical complexity and tougher syntactic analysis.
DTD: Document Type Declaration
Document Type Declarations in HTML are a thing of the past. But for completeness, I will still include a short discussion on them.
SGML (Standard Generalized Markup Language) is essentially the father** of all standard markup languages, including XML and HTML.
SGML has a thing called a (DTD) Document Type Declaration. Here’s an example of one:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">A Document Type Declaration links to a Document Type Definition, which basically defines the valid lexicon and syntax of the given SGML document.
This is because different versions of SGML have different notions of validity. That’s why every SGML document must specify its rules upfront with a DTD.
HTML was officially a subset of SGML up until HTML5.
“Why did HTML5 depart from SGML?”
See, a DTD imparts strict rules on the document. Web developers do not like that. Strict rules may have been good for the original intentions of SGML, but for HTML, it’s terrible.
Could you imagine if a webpage would show this, if you even slightly messed up your HTML?
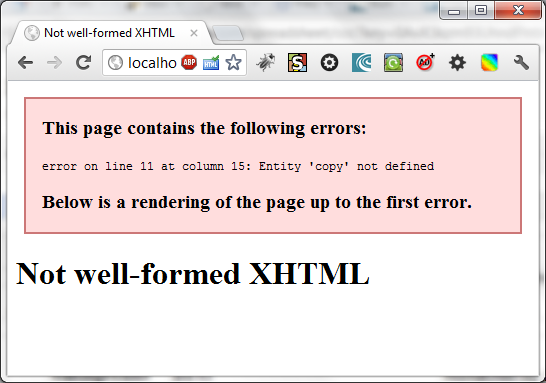
Considering that HTML may be dynamically produced by a server (and will inevitably have mistakes), you’d end up with these annoying red boxes everywhere.
It’s a terrible user experience.
That’s why web browsers started implementing error tolerance, which isn’t a part of SGML parsing. In addition, these error-tolerance rules exceeded the complexity of traditional SGML DTDefinitions.
Eventually, people decided that HTML shouldn’t be bound by the rules of SGML. After all, web browsers were already breaking away from SGML by implementing error tolerance.
Thus, the HTML5 specification was published, which officially instated standard error-handling algorithms for HTML parsers to implement. This is good because now, all compliant browsers handle HTML errors in the exact same way.
HTML5 is not SGML, and it no longer uses DTDs to define a schema.
However, you may have seen <!DOCTYPE html> in modern HTML documents. This isn’t a DTD in the traditional sense. It doesn’t link to a DTDefinition to define a schema.
Rather, it’s a vestige of HTML’s heritage from SGML.
However, its purpose is to enable standards mode over quirks mode, so it’s still important.
That’s all I have to say about parsing HTML. Up next — CSS parsing.
CSS PARSING
- Lexicon
- Syntax
- CSSOM Tree
- WebKit’s CSS Parser
Unlike HTML parsing, CSS parsing is relatively straightforward. It is a very simple language.
Lexicon
Here is the lexicon of CSS, taken from the W3C’s CSS2 Level 2 specification.

The macros encased in {} are defined as such:

Syntax
Here is the syntax of CSS Level 2, taken from the W3C’s CSS Level 2 specification.

CSSOM Tree
The parse tree of CSS is not exactly the CSSOM tree. The CSSOM tree is a CSS parse tree that is reformatted for consumption in the browser.
Keep that in mind when comparing the above lexicon to the CSSOM tree below.
Consider the following CSS file.
Its CSSOM Tree would be:

Each CSSStyleDeclaration Node is a dictionary that has entries for every possible CSS property. For the configured properties, the value is the given value. For the non-configured properties, the value is simply "".
WebKit’s CSS Parser
WebKit uses Flex and Bison to create its CSS Parser, in addition to its HTML Parser.
Flex consumes the lexicon described above in RegExps, and outputs a CSS Lexer.
Bison consumes the syntax described above in Backus-Naur Form, and outputs a CSS Parser (Syntactic Analyzer).
PARSING STYLESHEETS & SCRIPTS
- Stylesheets
- Scripts
- Speculative Parsing
The model of the web is synchronous. — Tali Garsiel
Stylesheets
The rendering engine parses HTML documents from the top-down.
When the rendering engine encounters a <style> element, it immediately parses the CSS within it; it ceases parsing of the HTML document, and focuses its attention to parsing the CSS rulesets. After it finishes parsing the CSS, it will return to parsing the main HTML document.
When the rendering engine encounters a <link> for a stylesheet, the Networking Component requests the linked stylesheet.
(I will assume that the <link> is in the <head> for simplicity. It typically is, unless you’re really optimizing for performance. This article isn’t about performance, and I don’t know much about performance optimization yet, either, so I will disregard the case where <link> is in the <body>.)
I believe*** that the rendering engine will continue to parse the rest of the HTML document past the <link>, while it’s waiting for the requested stylesheet.
Once the CSS file arrives, I believe that the rendering engine (which is single-threaded) ceases parsing of the HTML document and focuses its attention to parsing the CSS file. After it finishes parsing the CSS, it will return to parsing the main HTML document.
Scripts
(This section describes the traditional processing of <script> tags in HTML documents. Modern tricks and techniques complicate the situation. I will explain that later.)
When the rendering engine encounters a <script>, it ceases parsing of the HTML document.
If it is an inline script, the JS Engine component immediately executes the JavaScript. Once that is complete, the rendering engine returns to parsing the HTML document.
If it is an external script, the Networking component requests the given script. Once it arrives, the JS Engine executes it.
After the JS Engine finishes, the rendering engine continues parsing the HTML document past the <script>.
Having the rendering engine sit idly while waiting for network responses and the JS engine is pretty inefficient. That’s why it’s common practice to place <script>s right before the </body>. That way, all the HTML/CSS could be parsed and rendered to the screen while the JS is being fetched & executed.
The reason that the rendering engine ceases parsing the HTML/CSS past the <script> is because the <script> could potentially modify the HTML/CSS past the <script>. If the modification is major, there is no point in parsing past the <script> since so much will change anyway.
As a rhetorical question — why parse past the <script> if all that HTML/CSS could just change anyway? That’s wasted work.
It’s worth noting at this point that stylesheets can block the execution of JS.
Often, JS modifies styles. If you have a <script> tag near the top of your HTML, there is the possibility that you have CSS later in your document.
If your JS were to execute immediately, it could wind-up with incorrect information because it didn’t wait for style information to be added.
This caused a problem significant enough that Firefox, Chrome, and other browsers block scripts from executing if there are any stylesheets still loading/being parsed/undiscovered.
This is another reason to place your <link> and <style> tags near the top of your document and your <script> tags after them.
Speculative Parsing
Pretty quickly, browser developers realized that having the rendering engine sit idly for JS to be fetched & executed is inefficient. By 2011 at the latest (the year that Garsiel published her work), mainstream browsers were using speculative parsing.
Speculative parsing: when the rendering engine halts and the JS is being fetched and executed — a separate thread parses the rest of the HTML document for external resources (images, stylesheets, and other scripts), then requests them while the initial JS is being processed.
This shaves-off the network-request time of subsequent external resources.
It is called “speculative” parsing because there is a chance that the initial scripts modify the HTML document such that external resources later in the HTML document are discarded. In that case, fetching the subsequent resources is a waste.
Yet, the browser “speculates” that such an event is unlikely, and that it should continue fetching subsequent resources anyway.
4. Render Tree
- Render-Tree Nodes
- Render Tree ?= DOM Tree
- Constructing the Render Tree
- Style Computation
RENDER-TREE NODES
While the DOM Tree and the CSSOM Tree are being constructed, they are combined to form a third tree: the Render Tree.
This tree holds visual nodes (i.e. things that will actually appear on the page).
(Excludes <head>, <meta> , <script>, etc. unless you deliberately make them visible, elements with display: none, elements that are children of elements with display: none)
These nodes are called Render Objects/Renderers in WebKit (Chrome, Safari, Opera) and Frames in Gecko (Firefox).
For this article, I shall refer to them as Render-Tree Nodes to remain agnostic of rendering engines. Although, I will use the rendering-engine specific jargon when discussing WebKit or Gecko specifically.
WebKit has a class, RenderObject.h , that is the parent class of all other render object classes.
Garsiel provided a simplified version of RenderObject.h in her article, for educational purposes. The actual RenderObject.h, is much more complex, but for explanation’s sake, here is the simplified version that Garsiel showed in her original article.
RenderBox is one of the main subclasses of RenderObject . It represents the CSS Box of each DOM node that obeys the CSS Box Model (not everything obeys the CSS Box Model, such as inline SVGs).
RenderBox contains computed dimensional information, such as Box Model data including
heightwidthpaddingbordermargin
as well as other dimensional properties including
clientLeftclientTopclientWidthclientHeightoffsetLeftoffsetTopoffsetWidthoffsetHeightscrollLeftscrollTopscrollWidthscrollHeight
This is contrasted with some of the raw dimensional information specified via CSS, which is located in RenderStyle (seen in RenderObject.h above). This raw information doesn’t always match the computed dimensional information, because the Rendering Engine may override some of the dimensional values specified via CSS.
That’s why you’d see dimensional information in both RenderBox and RenderStyle, because RenderBox contains computed dimensional information and RenderStyle contains raw dimensional information — and they can sometimes be different.
There are various subclasses of RenderBox: RenderInline, RenderBlock, RenderListItem, etc.
A specific subclass of RenderBox is chosen for a given DOM node based on a few factors, primarily its display value. If a given DOM node has display: inline, it will use a RenderInline box. If it has a display: block, it will use a RenderBlock box, etc.
There is special case for replaced elements. According to MDN,
A replaced element is an element whose representation is outside the scope of CSS. These are a type of external object whose representation is independent of CSS.
Some examples will clarify the meaning of replaced element:
<iframe><video><embed><img>
I think of it this way: they are called “replaced” elements because their contents are replaced with some resource that is external to the HTML/CSS context.
These replaced elements have a special Render Object as well: RenderReplaced.
RENDER TREE ?= DOM TREE
There is obviously a strong correspondence between the Render Tree and the DOM Tree, however, it is not an exact, 1–to-1 correspondence.
There are 3 exceptions.
Exception 1: 0 Render-Tree Nodes per 1 DOM node
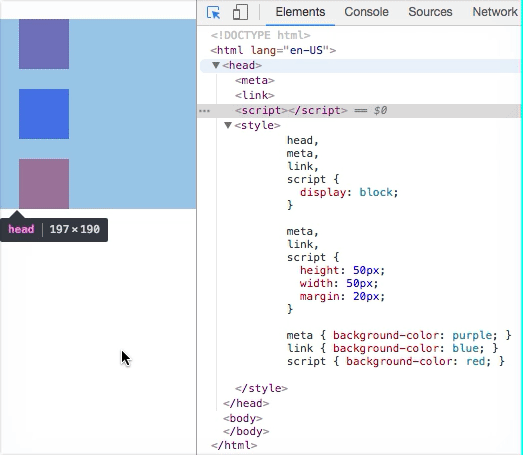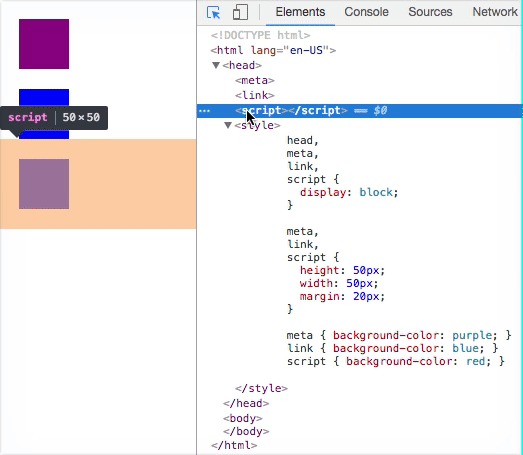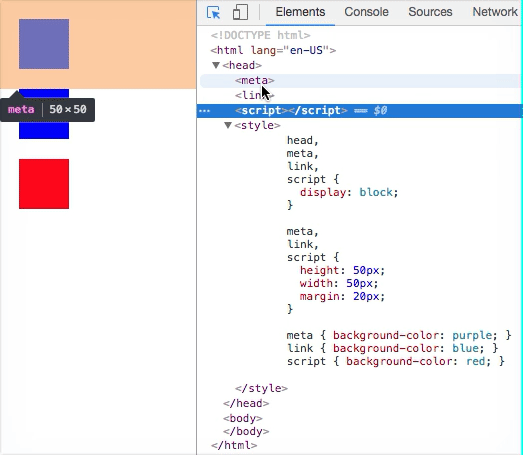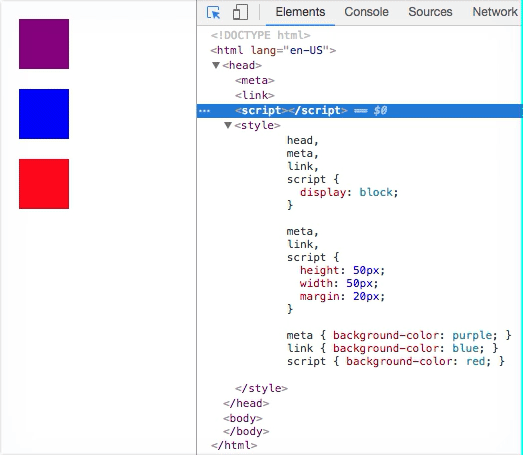
HTML Elements that have display: none do not have a corresponding Render-Tree Node.
Elements can have display: none explicitly set, or implicitly set. The explicit version is obvious: you set it via your CSS.
However, various elements have none as their initial value for the display property.
<head><meta><link><script>- etc.
These elements typically aren’t given Render-Tree Nodes because they have display: none by default. But you can override this and have them render. Doesn’t make sense to do this practically, but it’s worth noting.
Exception 2: 2+ Render-Tree Nodes per 1 DOM node
Some DOM nodes receive multiple Render-Tree Nodes.
Replaced Elements such as
<input type="color"><input type="date"><input type="file"><input type="range"><input type="radio"><input type="checkbox"><select>
all have multiple renderers for their multiple parts.
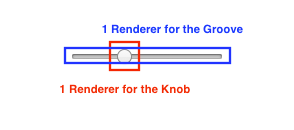
For instance , <input type="range"> has 1 renderer for the groove, and 1 renderer for the knob.
<select> has 1 renderer for the starting display box, 1 renderer for the dropdown list, and 1 for the button.


<input type="color"> has a crazy amount.

Exception 3: Incongruent Positions in Respective Trees
Normally, a DOM Node and its Render-Tree Nodeare located in same place in their respective trees.
But sometimes, this isn’t the case. When an element is floated or absolutely positioned (position: absolute OR position: fixed), the position of its DOM Node in the DOM tree doesn’t match the position of its Render Object in the Render Tree.
For instance, consider the following HTML:
<body>
<div>
<p>Lorem ipsum</p>
</div>
</body>Here is its corresponding DOM tree:
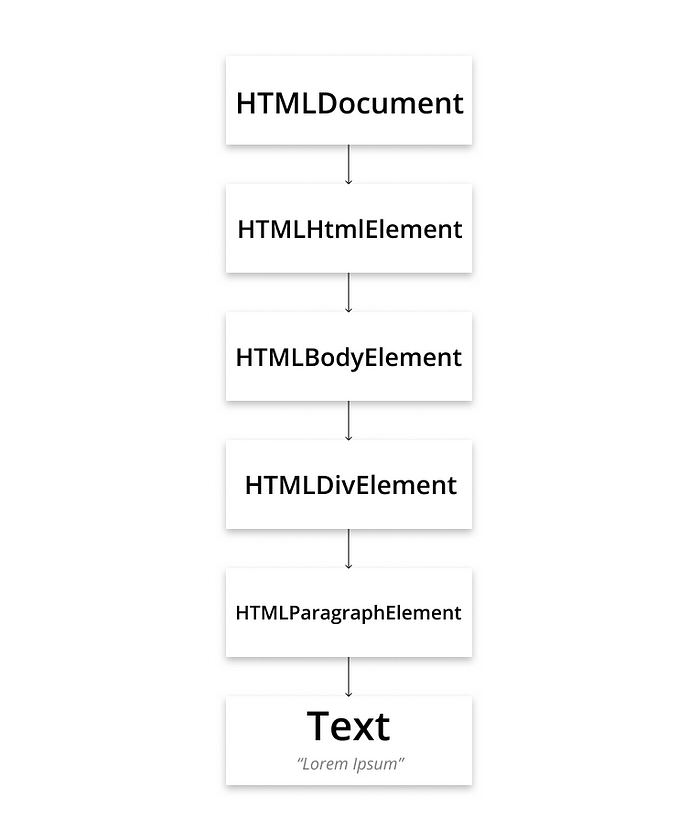
With just browser-default CSS, the corresponding Render Tree looks like:

However, if you were to float/absolutely position the HTMLParagraphElement, such as the following:
p {
position: absolute;
}the corresponding Render Tree would be:
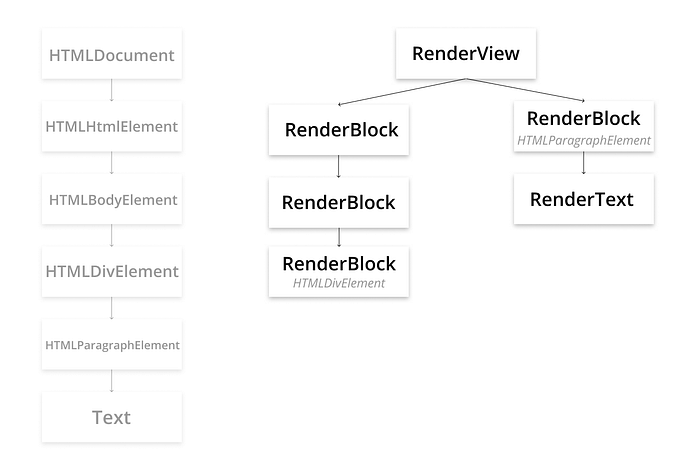
Because the HTMLParagraphElement is out of normal-flow, its RenderBlock is orphaned from HTMLDivElement's RenderBlock. Instead, it is adopted as a direct child of HTMLDocument's RenderView.
Therefore, all of the DOM nodes have corresponding Render-Tree Nodes, but they are in different locations in their respective trees.
CONSTRUCTING THE RENDER TREE
Gecko and Webkit handle Render Tree construction slightly differently.
Gecko adds a listener to DOM updates. When the DOM updates, the relevant DOM node is passed to a specialized object: FrameConstructor. FrameConstructor computes styles information for the DOM node & creates the appropriate Render-Tree Node(s) for the DOM node.
Gecko delegates style computation and Render-Tree Node construction to a specialized object, but WebKit takes a “self-service” approach; each DOM node is responsible for computing its own style information & constructing its own Render-Tree Node(s).
For WebKit, the process of style computation & Render-Tree Node construction is called attachment. Every DOM node is given a method called attach(), which initiates this process. Attachment is performed in a synchronous manner. Each DOM node calls its own attach() method upon being inserted into the DOM tree.
STYLE COMPUTATION
- Difficulties
- Difficulty #1: Lots of Style Data
- Difficulty #2: Matching Elements to Selectors
- Difficulty #3: Applying the Correct Styles
The rendering engine must know the visual information of a Render-Tree Node, before it can paint it onto the screen.
Visual information is computed from the style properties of each element.
Style properties are declared from multiple sources:
- Browser’s Default Stylesheets
- Page-author’s Stylesheets
- Inline
<style>elements style=""attributes
Difficulties
There are several difficulties with style computation:
- Style data is huge. It consumes a lot of memory.
- Matching elements to CSS selectors can exhibit poor performance if not optimized well.
- Applying the correct styles can be complex, given the cascading nature of CSS and multiple, conflicting CSS declarations.
Difficulty #1: Lots of Style Data
WebKit and Gecko address this issue in different ways.
WebKit — Shared Style Data
WebKit’s Render Objects hold references to RenderStyle objects, which hold the computed visual information for the given render object.
RenderStyle objects are shared by Render Objects under certain conditions, to save space & increase performance.
Some of the conditions are (see Garsiel’s article for an extended list):
- The elements are siblings or cousins.
- The elements are in the same “state”. E.g.
:hover,:active,:focusstates. - None of the elements have an
id. - The elements have the same “type”/tag name. E.g.
<div>or<th> - The elements have the same
classes. - None of the elements have inline styling via the
style=""attribute. - There are no sibling selectors used AT ALL. E.g.
div + p,div ~ p,:last-child,:first-child,:nth-child(),:nth-of-type(), etc.
If a single sibling selector is encountered, WebKit disables style-sharing for the entire document.
Gecko’s Rule Tree+Style Context Tree
Gecko creates 2 additional trees to improve style computation: the Rule Tree and the Style Context Tree.
The Rule Tree is a tree of CSS rulesets. Its branch’s nodes consist of CSS rulesets with overlapping CSS selectors. Deeper nodes have more specific selectors/are subsets of higher nodes.
Here’s an example.
Given the following HTML
And given the following CSS
The corresponding Rule Tree would be:

The Style Context Tree’s nodes are style contexts. Style contexts contain the end styles for each element.
So, it looks like the DOM Tree.
Style contexts are partitioned into structs. A struct is essentially a CSS property (E.g. border, color, font-size, etc.)
Style contexts are calculated from the Rule tree through the following process:
- Match each element to its most specific ruleset in the Rule Tree.

2. Add the properties/structs in those high-specificity rulesets to the style contexts.
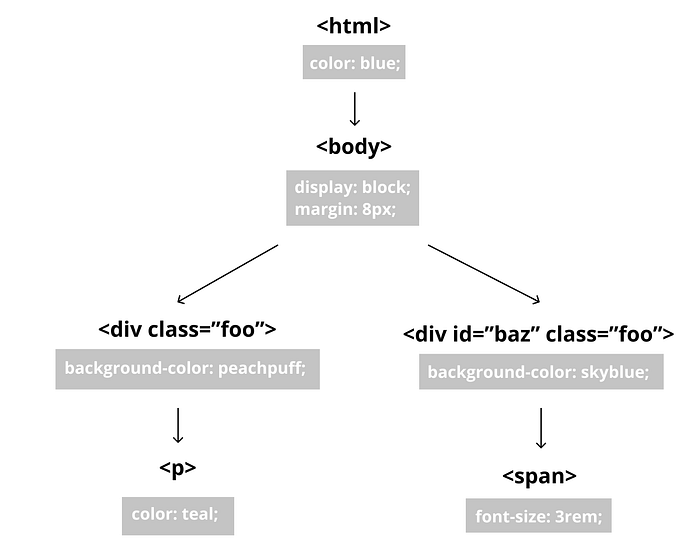
3. If there are unfilled structs (in this case, there are), traverse up the Rule Tree. Use the properties from these upper rulesets to fill remaining structs as much as possible.
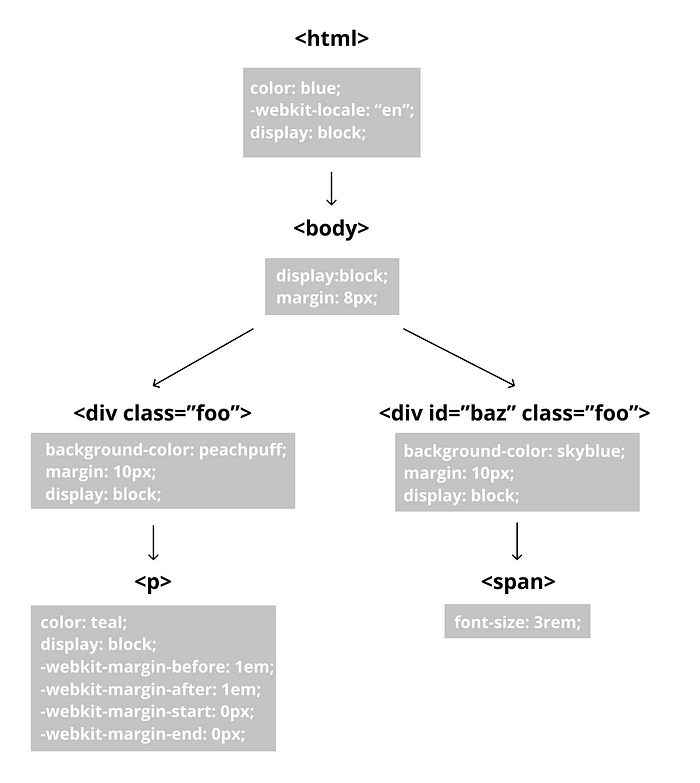
We’ve filled up more structs, but there are still much more to fill.
There are ~297 CSS properties (not including vendor-prefixed properties). So, it’d be rare for a stylesheet to specify all of them.
Assuming that there are still unfilled structs…
4. For each non-inherited struct, use the initial value specified in the W3C CSS Specifications.
These initial values (shown in dark) are cached somewhere. They are not duplicated for every style context. This results in a significant decrease in memory consumption.
5. For each inherited struct, point to the parent context’s value.

As you can start to see, there are many opportunities to share style contexts and reap massive memory optimizations.
This is especially true with sibling elements. Sibling elements can often share ENTIRE STYLE CONTEXTS. E.g. <li> elements. They are often identically styled, so they typically share the same style context.
Difficulty #2: Matching Elements to Selectors
There are 3 sources for CSS styles:
- CSS Rules (external via
<link>or internal via<style>) - Inline Style Attributes (
<div style="background-color: goldenrod;">) - Specific Style Attributes (
bgcolor="red",valign="baseline", etc.)
These are deprecated. Don’t use them.
When it comes to matching elements with styles, #2 and #3 are trivial. The styles apply to the element they’re attached to.
#1 is worthy of discussion — from a performance perspective.
The styles in CSS rulesets use selectors to match elements. Determining which elements to match is the easy part. id selectors match elements with the corresponding id. class selectors match elements with the corresponding class. Type selectors ( p, div, dl, progress ) match elements of the corresponding type. So on and so forth.
But how to match elements is the hard part. If you match elements naïvely, you would have some major performance problems.
Example of Naïve Solution: For every CSS ruleset, loop through every element to determine which ones it should apply to.
This would yield awful performance.
So how do browsers match elements to selectors?
Before the browser begins parsing CSS rules, 4 hashmaps are created. These hashmaps will store the CSS rules. Each hashmap stores a different category of CSS rules, based on their selectors.
- ID-selector CSS Rules
- Class-selector CSS Rules
- Type-selector CSS Rules
- Miscellaneous-selector CSS Rules
This drastically improves the performance of element-selector matching.
You simply lookup an element’s corresponding CSS rulesets by using its ID/Class/Type/etc. as keys.
Webkit and Gecko both implement this optimization.
Difficulty #3: Applying Styles in the Correct Order
Very frequently, an element’s style property is declared more than once.
Example:
div p {
color: goldenrod;
}p {
color: red;
}
In what order do you apply these?
If you apply rule 1 first, then rule 2 second, you’ll have color: red.color: goldenrod would be overwritten.
If you apply rule 2 first, then rule 1 second, you’ll have color: goldenrod. color: red would be overwritten.
The order of style-application is known as the cascading order. It is fundamental to CSS’s nature. It’s even in the name!
According to the CSS2 Specification, § 6.4.1 Cascading Order, the cascading order is (in ascending priority):
- User Agent Declarations (Browser Defaults)
- User Normal Declarations
(Browser users can actually set custom styles for themselves. For example, a vision-impaired user might set a default offont-size: 30pxfor all websites they visit. This is what a “User” declaration is. Don’t confuse this with “User Agent” declarations. “User Agent” means browser.) - Author Normal Declarations
(The styles that you, a page author/web developer, set.) - Author
!importantDeclarations - User
!importantDeclarations
(This is to provide the user with ultimate control over presentation. This is especially useful for people with accessibility demands.)
If two declarations fit the same order, (E.g. they are both User Normal Declarations), then sort by SPECIFICITY.
If two declarations fit the same order AND specificity, then sort by position in the stylesheet(s). The declaration that occurs later in the stylesheet(s) shall apply.
Specificity
The specificity of a declaration is a 4 digit number, a b c d.
Example:
#foo .bar > [name="baz"]::first-line {} /* Specificity: 0 1 2 1 */You concatenate these numbers ( 0 1 2 1 => 121 ). Then you sort these numbers in ascending order. The higher number wins.
How do we calculate these numbers?
a:
Set to1if the declaration originates from astyle=""attribute.
Set to0otherwise.b:
Count the # of ID selectors in the overall selector. That number is the value forb.c:
Count the # of class selectors, attribute selectors, and pseudo-classes in the overall selector. That number is the value forc.d:
Count the # of type selectors and pseudo-elements in the overall selector. That number is the value ford.
With this knowledge, here are some examples (taken from the CSS2 spec).
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */VERY IMPORTANT POINT: The base/radix of the specificity is NOT NECESSARILY 10. You could have a specificity of 0EF9, which would hypothetically have a radix of 16 (Hexadecimal).
The specificity radix grows as needed. If you wrote a selector 297 type selectors within it, then your radix would be 297 (assuming no other count surpasses 297). If your largest count in a given digit were only 3, then your radix would be 3.
If the radix were locked at 10, you would have carry-over to the left digit. That would create confusing situations.
Gradual Process
Recall that rendering+painting is a gradual process. The browser won’t wait to parse every HTML document and stylesheet before rendering+painting.
If a given DOM node’s styles haven’t loaded (due to network latency) by the time <DOM node>.attach() is called, default placeholder-styles are used. The DOM node is flagged and its styles will update when they load.
5. Layout
- Dirty Bit System
- Global & Local Layout
- Asynchronous & Synchronous Layout
- The Layout Process
Upon creating a render object, it does not have a position or dimensions.
Layout is the calculation of these values.
HTML uses an intuitive flow-based layout model by default. This means that elements are laid-out in the order that they appear: left-to-right, top-to-bottom.
Typically, elements “later” in the flow don’t affect elements “earlier” in the flow. So, for simple situations, only a single pass is necessary to lay out all elements. Some layout models such as display: table (and I think display: flex and display: grid ) may require multiple passes.
For positioning, the coordinate system is relative to the root render object. Typically, this is the HTMLDocument's render object. (HTMLDocument is the parent node of HTMLHtmlElement, the DOM node for <html>. It always wraps the HTMLHtmlElement.)
A render object’s position is the position of its top-left corner.
The root render object’s position is (0,0), and its dimensions are the viewport’s dimensions. (The viewport is the portion of the browser window that displays webpages.)
Layout is a recursive process.
Each render object has a layout() method. So first, the root render object is laid-out. Then, it lays out its children by calling their layout() methods. Its children layout their children (RRO’s grandchildren). So on and so forth.
DIRTY BIT SYSTEM
Consider a webpage in the middle of its lifecycle — after its initial layout.
Suppose a DOM node’s style is changed. This change will affect layout. How do you handle this? Do you perform a Global relayout? Or do you perform a local relayout on the relevant render objects?
Ideally, you’d just perform a local layout. (But sometimes, you need to perform a global layout, because the change affects neighbor render objects).
To perform a local layout, you need the ability to distinguish dirty render objects from clean ones.
To attain this ability, browsers flag specific render objects as dirty if they require layout due to some change.
Actually, there are 2 types of dirty flags: dirty self & dirty children.
A dirty-self flag indicates that the render object itself requires layout.
A dirty-children flag indicates that 1+ of the render object’s children require layout. The render object itself may be clean.
GLOBAL & LOCAL LAYOUT
Global layout is required when changes affect all render objects.
Examples:
- A global style change, like changing all
font-familyorfont-sizevalues. - Resizing the screen.
(Bolded b/c it’s not obvious that a non-stylistic change could force global layout.)
Local layout only targets dirty render objects. It’s performed asynchronously by the rendering engine, which is single-threaded.
ASYNCHRONOUS & SYNCHRONOUS LAYOUT
Global layouts are almost always synchronous.
Local layouts are performed asynchronously and in batches by default. The rendering engine will attempt to group several pending layouts, then apply them asynchronously in 1 sweep. This is to improve performance. Applying many individual layout + paint procedures would yield poor performance. Whereas applying all the layouts, then painting once is better.
However, there is a situation that forces local layouts to perform synchronously:
scripts demanding style information, like clientWidth.
In such situations, the script must immediately know style information that is up-to-date. The pending layout cannot be performed asynchronously at a later time. It must be performed now because a <script> is waiting for it, in order to obtain up-to-date style information.
Therefore, because the rendering engine and the JS engine share the same thread, the demanding script will immediately halt, wait for the layout to apply, then resume.
Poorly written scripts can cause many synchronous, individual local layouts. This is known as layout thrashing. Avoid this when possible.
THE LAYOUT PROCESS
Layout is typically performed as such. For each render object:
- The given render object determines its width.
(This derives from the containing block’s width, the render object’s width style-property, and the render object’s margin and borders.) - For each of its child render objects,
1. Position the child render object.
2. Layout the child render object if needed.
Often, when the webpage is en media res, child render objects are clean; their dimensions don’t need to be recalculated. But if they are dirty, or if a global layout is occurring, they will need relayout. - Sum the child render objects’ heights. Set the parent render object’s height to this cumulative height.
- Flag the given render object as clean.
6. Painting
- Global & Local Painting
- The Painting Order
- Webkit’s Bitmap Deltas
- The Rendering Engine’s Threads
- Event Loop
GLOBAL & LOCAL PAINTING
Similar to the rendering process, painting can either be global or local. Regions of the content are flagged as dirty to enable local paints. Then, the rendering engine invokes the UI Backend component of the browser to actually repaint the dirty regions. Recall that the UI Backend relies on the host OS’s API to paint content onto the screen.
THE PAINTING ORDER
Render objects have many layers on the z-axis. Their painting order (from back to front) is:
- Background Color
- Background Image
- Border
- Children Render Objects
- Outline
WEBKIT’S BITMAP DELTAS
For a given painting-region, WebKit will record it as a bitmap. When the painting-region becomes dirty, WebKit won’t repaint the entire region. It will only paint the deltas from the old bitmap to the new bitmap. This provides some optimization.
THE RENDERING ENGINE’S THREADS
As I mentioned earlier, the rendering engine is single-threaded. Also, it shared the same thread as the JS Engine of a browser. This godlike thread is known as the browser’s main thread. Networking occurs in a separate thread.

EVENT LOOP
The browser’s main thread uses an event loop to handle asynchrony. It’s an infinite loop that pulls tasks such as layout, painting, and JS execution from a message queue and processes them.
7. CSS Visual Model
- The Canvas
- CSS Box Model
- Positioning Scheme
- Box Types
- Positioning
THE CANVAS
The Canvas is a term used in the CSS specification. It describes the “theoretically infinite space” where content is painted to. You view the canvas via your viewport.
CSS BOX MODEL
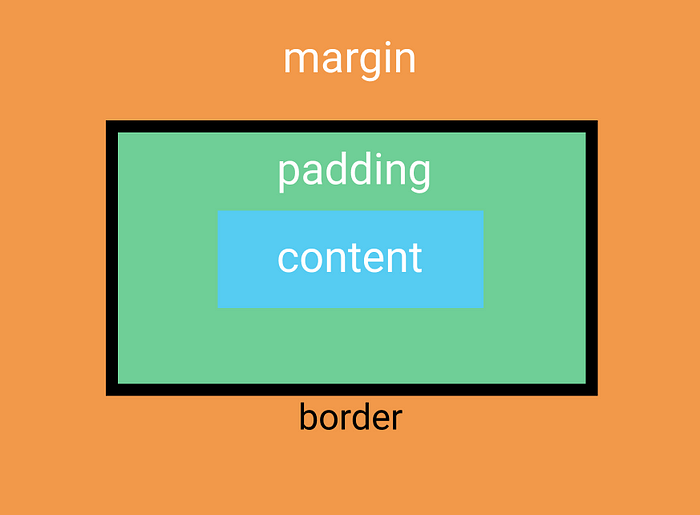
The Box Model specifies the structure for CSS Boxes created for each rendered (e.g. not display: none) HTML element in a document.
There are 4 components:
- Content
Typically text. Can be images/video/etc. for replaced elements. - Padding
Whitespace between the content and the border. - Border
- Margin
Whitespace outside the border. Mostly used to distance a CSS box from other boxes.
The following image depicts the fundamental CSS box. There are other derivatives of this box, but this is the basic one.
POSITIONING SCHEME
The Positioning Scheme is one of the most important factors in CSS layout. There are 3 positioning schemes:
- Normal Flow
This is the “intuitive” flow-based layout I discussed earlier. Each CSS box’s position corresponds to its HTML element’s position in the DOM. - Floats
The box is removed from normal flow, then moved as far right/left as possible. Adjacent content may flow around the box. - Absolute Positioning
The box is removed from normal flow entirely (it does not affect adjacent content at all). It is assigned a position relative to the containing block.
The choice of positioning scheme is influenced by the position and float properties.
position: staticandposition: relativeyield normal flow.position: absoluteandposition: fixedyield absolute positioning.float: leftandfloat: rightyield floats.
A CSS box’s position is influenced by
- Box Type & Box Dimensions
Positionvalue- External info such as image size and viewport size
BOX TYPES & BOX DIMENSIONS
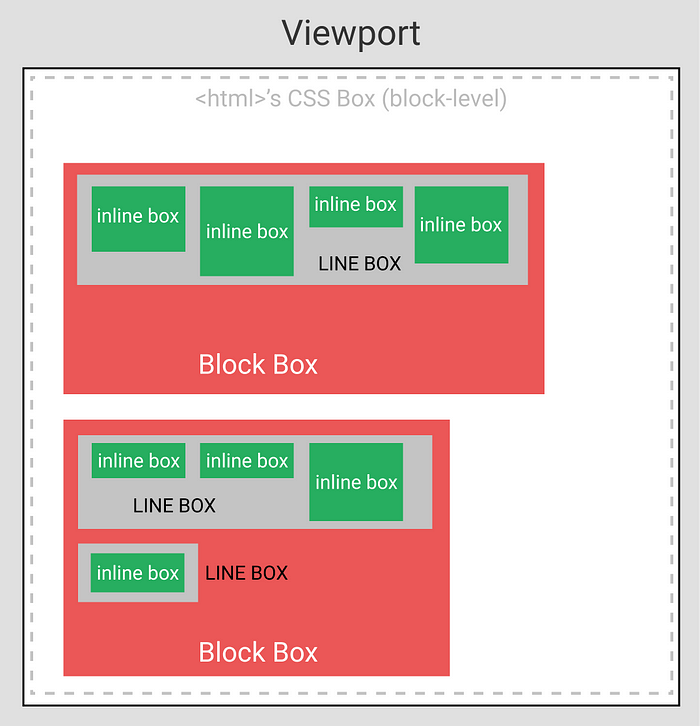
Block-level boxes form new “blocks” of content. Also, they almost always act as a block container box for other boxes. A box that is block-level + block container is known as a block box.

Inline-level boxes do not form new blocks. Their content is distributed in lines. They reside within block container boxes, and participate in their inline formatting contexts.
Additionally, an intermediary box spawns between the block container box and the inline-level boxes: a line box.
The line box is responsible for distributing inline content on lines, within block container boxes. When you use vertical-align and text-align on inline-level elements, you are manipulating their corresponding inline-level boxes — you manipulate their positioning within these line boxes.
POSITION VALUE
position: relative boxes occupy space as if they were position: static. Then, the box itself is shifted as specified by top, right, bottom, and left.
A box with float: left or float: right is removed from normal flow. It moved as far left/right as possible on its current “line” (not line box). Adjacent line boxes are shortened to accommodate the floated box. This is what causes surrounding text to flow around the floated box.
position: absolute boxes are removed from normal flow. They are positioned relative to the nearest ancestor box that has a non-static position value (This is why you sometimes see random ancestor boxes with position: relative, but no top, right, bottom, or left values. The position: relative exists simply to influence descendant boxes with position: absolute.)
If no ancestor boxes have a non-static position value, the “initial container box” is used: the <html> element’s box.
position: fixed boxes are removed from normal flow. They are positioned relative to the viewport.
Conclusion
It is midnight, 2 days before my finals. I should be studying for those, but I had a burning urge to finish this article here and now. I’ve been working on it incrementally for months.
While this originally started as my notes on Tali Garsiel’s article, I believe I added enough unique content and summaries such that this article has a substantial raison d’être.
These articles are primarily for my future reference, but perhaps someone out there might gain something from these notes, so that’s why I publish them.
Hope you enjoy!
References:
- https://www.quora.com/What-is-the-difference-between-regular-language-and-context-free-language
- https://stackoverflow.com/questions/5175840/is-html-a-context-free-language
- https://stackoverflow.com/questions/898489/what-programming-languages-are-context-free
- https://www.html5rocks.com/en/tutorials/internals/howbrowserswork/
- http://grosskurth.ca/papers/browser-refarch.pdf
- https://en.wikipedia.org/wiki/Parse_tree
- https://html.spec.whatwg.org/multipage/parsing.html#parse-errors
- https://html.spec.whatwg.org/multipage/parsing.html#tokenization
- https://www.w3.org/QA/2002/04/valid-dtd-list.html
- https://www.w3.org/TR/CSS2/syndata.html#tokenization
- https://developer.mozilla.org/en-US/docs/Web/HTML/Optimizing_your_pages_for_speculative_parsing
- https://stackoverflow.com/questions/34269416/when-does-parsing-html-dom-tree-happen
- https://developer.mozilla.org/en-US/docs/Web/CSS/Replaced_element
- https://trac.webkit.org/browser/webkit/trunk/Source/WebCore/rendering
- https://hacks.mozilla.org/2017/08/inside-a-super-fast-css-engine-quantum-css-aka-stylo/
- https://developer.mozilla.org/en-US/docs/Style_System_Overview#Style_data_cached_in_style_context_tree
- https://www.chromium.org/developers/the-rendering-critical-path#TOC-Browser-Thread-Architecture
- https://www.w3.org/TR/CSS22/visuren.html
*It is odd that this machine shares the same name as the parent process: parsing. It’s a rather nebulous name. I would have gone with “syntaxer”, so that a parser = lexer + syntaxer. :P
**There are older ancestors such as IBM’s Generalized Markup Language.
***I couldn’t find a source for this. However, I believe this is true because “it seems that since style sheets don’t change the DOM tree, there is no reason to wait for them and stop the document parsing” — Tali Garsiel. If you know the answer, please comment below.
Opinions expressed in these articles do not reflect those of my employer.

