JSON vs Protocol Buffers vs FlatBuffers
Up until an year ago, I was pretty comfortable using JSON for all the inter-service and intra-service communications. I didn’t even knew that the latter two even existed. To be honest, these sounded like buzzwords and didn’t seems to be of any practical importance. But I couldn’t have been more wrong.
What are Protocol Buffers?
As explained on https://developers.google.com/protocol-buffers/
Protocol buffers are Google’s language-neutral, platform-neutral, extensible mechanism for serializing structured data — think XML, but smaller, faster, and simpler. You define how you want your data to be structured once, then you can use special generated source code to easily write and read your structured data to and from a variety of data streams and using a variety of languages.
In layman terms, you define a schema (in a .proto file) and then protocol buffers generates the code for you in any of the supported languages (which covers almost all of the mainstream languages).
The advantage of using protocol buffers is that it
- Gurantees type-safety
- Prevents schema-violations
- Gives you simple accessors
- Fast serialization/deserialization
- Backward compatibility
Protocol Buffers are good for communicating between two systems (e.g. microservices). Google’s GRPC is doing exactly this for developing a high performance RPC framework.
But Protobufs (short for protocol buffers) are not good for the purposes of storing something e.g. a text document, or a database dump.
This is because in the native format protocol buffers are not human-readable and human-editable. Without an accompanying schema, you can’t make sense of a protocol buffer.
What are Flat Buffers?
In concept, Flat Buffers are similar to Protocol Buffers. It’s also a google project aimed at making language neutral serialization mechanism which is fast.
The primary difference between protobufs and flat buffers is that you don’t need to deserialize the whole data in the latter before accessing an object. This makes flat buffers responsible for use cases where you have a lot of data and you are concerned with a snippet of it. It also consumes much less memory than protobuf.
The code is also an order of magnitude smaller and supports more schema features (e.g. unions of types in XML)
Flatbuffers also suffer from the same drawback as protobuf due to lack of human-readable representation.
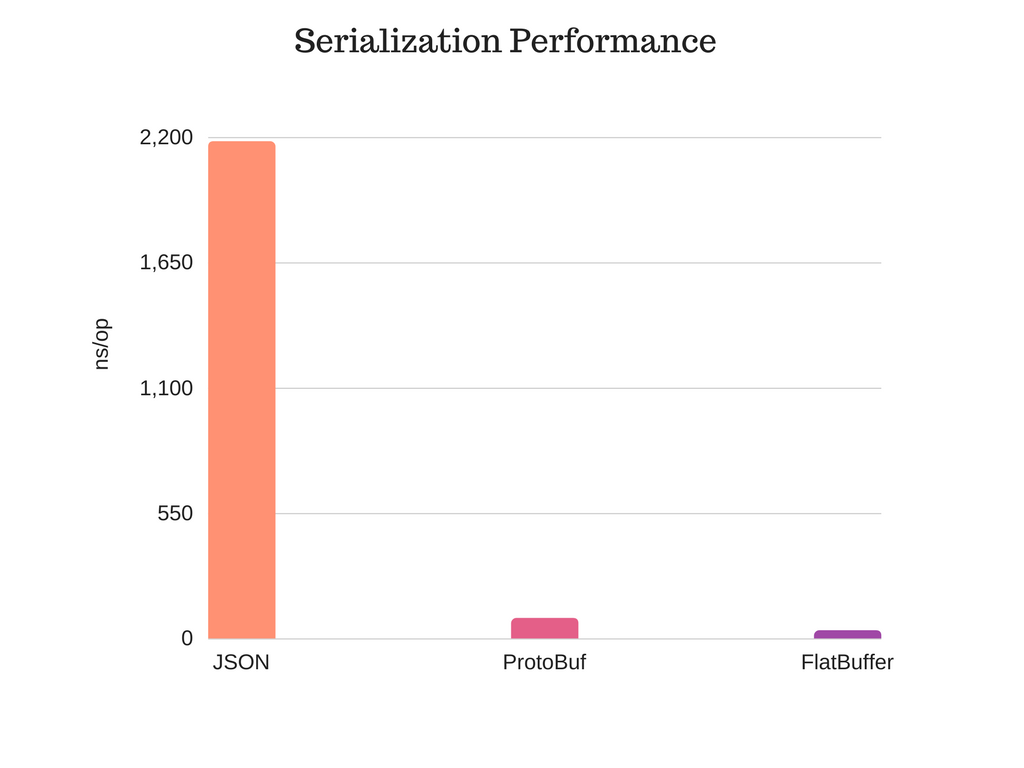
Performance
The performance test was done using JMH-Benchmark in Java8 on Macbook Pro (13-inch, Early 2015) edition with specs:
- 2.7 GHz Intel Core i5
- 8 GB 1867 MHz DDR3
The library for JSON processing used is Jackson. You can definitely achieve better JSON performance using libraries such as DSL-JSON or rapid JSON. But these libraries are not as popular as jackson which is used in most of the libraries these days and supports almost all of the datatypes and even Scala Objects and joda-time.

Which one to use?
For storing data in DB or in filesystems such as S3, JSON should be the obvious choice. This is because it allows you to query these systems without writing additional code using already available tools. For squeezing more data, you can always use GZIP or LZ4 compression which is supported out of the box in most of the systems these days.
However for inter-communications between various REST services or streaming systems (e.g. Kafka) , you should prefer protocol buffers or flat buffers. This is because of the significant difference between the serialization/deserialization performance of these two vs JSON which I’ll show later. Also, the memory footprint is much smaller in flatbuffers.
Flatbuffers should only be used for cases where the object is large and you normally need to extract only one or two entities out of it. This is because the code for making a flatbuffer object is much more than that needed for protobuf and JSON. Even converting from/to JSON is not supported in flatbuffers which is essential for logging in many cases.
If you need any more comparisons or more details on how to use protobuf, drop a mail and connect with me on LinkedIn, if you are interested in working on interesting stuff as this.
Ciao!

✉️ Subscribe to CodeBurst’s once-weekly Email Blast, 🐦 Follow CodeBurst on Twitter, view 🗺️ The 2018 Web Developer Roadmap, and 🕸️ Learn Full Stack Web Development.

