Making sense of the RAFT Distributed Consensus Algorithm — Part 1

The goal of The Series
There are many articles on Raft however most of them are short, theoretical, and not detailed. Consensus algorithms is an area where shortcut analysis does not work as the topic is pretty hard to understand. While reading the raft paper and many articles, I found out that no code and not playing with a Raft simulator makes it even harder to understand.
So this series of articles intends to be more natural and lucid from an engineering perspective — it thoroughly explains concepts, core algorithms with code and simulates some important use cases. It also answers several questions at times when needed to make concepts clear.
I would like to encourage you not to rush and take enough time to think through different concepts, algorithms and use cases as you go through this series.
The Problem
The Oxford dictionary defines consensus as:
an opinion that all members of a group agree with
Human face consensus issues all the time — going for a lunch with a group of office friends? You must decide a time & most probably at least one of your friends opposes the time because he has a production deployment going on. Another friend might join you 15 minutes late as he has a long overlapping meeting & you feel lonely without him :| If majority of your friends are busy & don’t agree on a time, your plan gets cancelled & you re-plan tomorrow or so.
The same is true in distributed systems as well — you have a group of servers which need to agree on some state for a given piece of data. To make things worse, the servers are typically spread across geography.
Why do we need consensus
Most of us have used relation database like MySQL, Oracle at least once in our programming life. When you INSERT or UPDATE a value & then perform a SELECT on that, you get the latest value back — it happens typically because we use a single machine to contain all our data. Now imagine, you have a huge amount of data partitioned across 10 machines. For better availability of data, you have enabled replication of data. Say a piece of data is replicated across 3 machines & you want to query the data from any part of the world because your app is global, so a query can reach any suitable replica for a particular data. Now, what if you INSERT or UPDATE a data, but when you do SELECT, you don’t get back the latest value — basically your write request is served by machine W while the read request is served by a replica R . Unfortunately, say, not getting the latest value is unacceptable in your use case. To resolve this problem, we need a mechanism through which multiple servers would agree on a value & irrespective of whichever machine serves your SELECT request, you get the same result back every time. In short, you need a coherent view of your distributed system so that it behaves as if only a single machine is serving all requests. That’s where we need consensus.
If you want to build a strongly consistent distributed system ( CP system in terms of CAP theorem ), you need to have consensus.
Raft to the Rescue
Raft (Replicated & Fault Tolerant) is an algorithm / protocol which solves this problem. It came out of a PhD thesis by Diego Ongaro & John Ousterhout at Stanford University in 2014. Raft is designed to be easily understandable, the predecessor algorithms like Paxos & Multi-Paxos which are very well known consensus algorithms, known to be very difficult to understand, maybe only a handful of people in the world understand them properly — at least this is what the authors of Raft claim. If you follow through this entire series & understand most of it, then probably you understand Raft, then the authors’ claim stands true.
There is no standard implementation of Raft, it just defines several steps to achieve consensus in a fault tolerant way. There are hundreds of implementation of Raft already for different use cases. Most of the engineers won’t need to implement any consensus algorithm in their lifetime but it does not hurt to understand the heart of distributed systems, you’ll see in this series how consensus is a hard problem to solve, you’ll get a view of the critical edge cases that arise in distributed systems all the time which will definitely ignite your thought process & help you become a better system designer.
We won’t discuss any mathematical correctness of the algorithm, however, using different use cases we’ll see how Raft actually works. We’ll also discuss few important algorithms in details with code for a better understanding.
Q. How is Raft implemented?
A. Raft is typically implemented as a module inside a service like a distributed database or etcd like distributed key value store etc. Raft itself is not implemented as a service or micro service. It just works like a background process in the system.
Prerequisite Concepts
Before we get into the details of Raft, understand the following concepts well. We’ll discuss these concepts enough for a fair understanding & we’ll use the terminologies throughout this series thereafter.
Quorum
If your distributed system has N nodes, you need at least (N/2) + 1 nodes to agree on a value — basically you need majority (more than 50%) votes from for consensus just like any country’s constitutional election. Majority vote ensures that when (N/2) + 1 nodes are running & responding, at least one node contains latest value for a given data across read & write requests even if there is a network partition or other failure in the system.
Q. How many node failures we can tolerate when we have a quorum based system with N nodes?
A. If N is odd, we can endure N/2 node failures. If N is even, we can endure (N/2)-1 node failures.
Following is a simple table to state the fact:
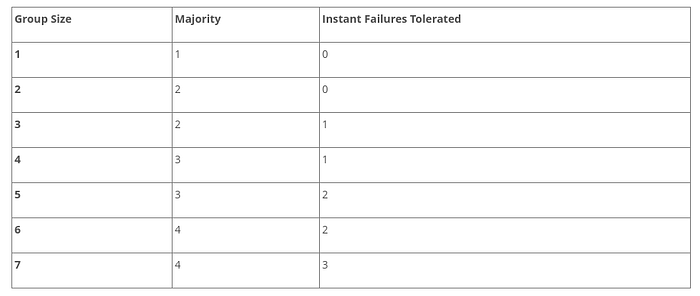
Q. Should you choose an even number or odd number for N in production?
A. Consider N = 4 , according to the above table, majority required is 3 & you can tolerate only 1 node failure. For N = 5, majority is still 3 but you can tolerate 2 node failures. So from failure handling perspective, even number of nodes does not add much value as fault tolerance is lesser. So it’s better to choose odd number nodes in production at the expense of little higher cost — you can tolerate more node failure just in case it’s a bad day for you.
Q. What is the worst value for N in production?
A. If N = 1 or N = 2 & you lose a node, you lose the whole system since you practically can’t tolerate any node failure at all. In fact for N = 2, you have actually doubled your single point of failures in the system — if any node goes down, your whole system is down. So choose an odd value N ≥ 3 in production.
Q. What is a good value for N in production?
A. The figure obviously depends on your estimation of data, bandwidth, throughput & cost requirement. However, 5 seems to be a good number as you can manage 1 node failure & 1 node can be down for maintenance ( total 2 nodes down ) while 3 nodes are still up & running.
Q. What happens if majority of nodes is unavailable?
A. Ideally your system may stop responding completely depending on how you configure read & write use cases. Typically write stops completely but available nodes may still serve read requests in case you design read requests to be eventually consistent.
Node States
Raft nodes can be in three states: Leader, Follower & Candidate. We’ll see in later section how node transition happens. For now just remember the fact that Raft is strongly a leader based consensus protocol. Leader is the source of truth. Logs always flow from the leader to the followers.
Log
This is not a regular log file that you use in your application for information & debugging purpose. However the concept is more or less same. A log is a disk based file where usually objects called log entries are added sequentially in form of binary data.
Committed & Uncommitted Log
- A log entry is committed only when it gets replicated by the majority nodes in the cluster. A committed log never gets overridden. A committed log is durable & eventually gets executed by all the nodes in the Raft cluster.
- If a client command / log entry is not yet replicated to the majority of the cluster nodes, it’s called uncommitted log. Uncommitted logs can be overridden in a follower node.
State Machine
Don’t get scared by this term. State machines can be really complex in nature. Typically it means — depending on an input fed to the system, the state of a data (key) changes. In Raft context, think as if this is just like a module which stores the final agreed value for a key. Each node has its own state machine. Raft has to make sure whatever log entry is committed, they get eventually applied to the state machine which works as a source of truth for the data in memory. For fault tolerance, the state machine can be persisted as well.
Term
A term represents a time period through which a node acts as a leader, the concept is based on logical time (not a global time) — it’s just a counter managed by every node individually. Once a term terminates, another term starts with a new leader. Even though at a given point in time, terms across nodes may differ, Raft has a mechanism to sync & converge them to the same value.
The term is also called lease or leader lease, just another name it is.
RPC
Just like your Facebook mobile app communicates with Facebook server through REST API on top of HTTP, nodes participating in Raft communicate with each other using Remote Procedure Call (RPC) on top of TCP. This protocol is suitable for communication across data centres, internal systems & services (not user facing products or services).
Raft uses two different RPC requests. At a high level:
- RequestVote (RV): When a node wants to become a leader, it asks other nodes to vote for it by sending this request.
- AppendEntries (AE): Through this message, a leader asks the followers to add an entry to their log file. The leader can send empty message as well as a heartbeat indicating to the followers that it’s still alive.
How it works
For our explanation, we’ll use a 5 node cluster.
Raft works on the concept of distributed log replication. In order to gain consensus on some state for a log entry, Raft cluster has to choose its leader first, then majority of the followers mimic exact logs from the leader — this ensures logs across nodes are in the same order as the leader. At a time, there would be only one active leader in the system (unless there is a network partition that could cause existence of multiple leaders or possibly no leaders at all) & it’s the source of truth for all logs.
Raft separates leader election from log replication process. Without leader, Raft can’t function. So leader election becomes a mandatory step in the absence of a leader.
Q. What are the major advantages of leader based system?
A. The system becomes simple to understand & operate when the abstraction is based on leader. Clients typically interacts through the leader & the leader takes care of important decision making, metadata state of the system.
Q. What are the major disadvantages of leader based system?
A. The leader becomes a single point of failure. So the system should be able to quickly react to choose another leader when the current one fails. Also since all client interactions happens through the leader, the system might become slower at scale.
Some Raft Design Decisions
Let’s look at few important design decisions which are very core to the protocol.
Random Timeout
Raft uses concept of random Election Timeout — the amount of time a follower waits until becoming a candidate ( see Figure 3 for more details on state transition ). When a cluster bootstraps, every node picks a random timeout between 150 & 300 milliseconds inclusive for itself & it starts counting down the timeout. There are now 2 possibilities:
- Before the node times out, it receives a message from another node — it might be a heartbeat or log replication message from the leader or voting request from another peer. In this case, the timeout gets reset & the count down starts again.
- The node does not receive any message at all during the timeout.
Q. Why to choose random timeout?
A. Imagine all of the nodes have a fixed timeout. So in the absence of a leader, they timeout at the same time & there would be no guarantee of leader election since the process can repeat multiple times or indefinitely & all nodes starts counting down the same timeout value again. So randomization helps here. In case the leader is still undecided, the process starts again with a new set of random timeout across nodes & eventually we would have a leader. It’s highly unlikely that we won’t have a leader chosen after a trial or two.
Term Lifetime
When there is no leader in the cluster & a node X times out, it initiates a new election term, increments its term to T by adding 1 to previous term’s value. Just to remind you — a term is a local counter managed by all the nodes. There are again 2 cases here:
- If
Xis elected as the new leader, termTcontinues i.e; all the new log entries added to the leaderX& thereafter are propagated to the followers with termT. Xloses the election, a new election begins with new termUwhereU > T.
So pictorially, a terms graph looks like below:
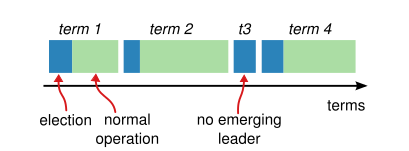
In the above diagram, term 1 starts when the cluster starts up. A leader is elected for term 1 & normal operations like log replication, heartbeat continues till the term 1 ends. The leader dies. Node X increases its term to 2 , gets elected as the new leader & term 2 continues. Now X also dies at some point, some other node Y starts the election process, increases the term to 3, but unfortunately the election fails to choose a leader resulting in term 3 termination. And the process goes on.
We’ll discuss three major sections in this series of articles:
- Basic leader election (the first leader election) when the cluster starts up, nodes are fresh & no log is present yet in the system.
- Raft log replication process.
- Leader election when nodes already have some logs.
The First Leader Election
As mentioned earlier, a node can be in different states depending on the cluster situation. Let’s look at the following diagram to understand the state transition.

- Each node starts from the
Followerstate. Once election time out gets over, it enters intoCandidatestate — it means the node is now an eligible candidate to become a leader. - Once a candidate gets clear majority votes, it enters into the
Leaderstate. - If there is no clear winner during the election process, the candidate times out again, remains in the
Candidatestate & a new election begins. - If a candidate gets a message from a newly leader, it steps down and becomes a
Follower. - If there is a network partition, the current leader might get disconnected from the majority of the cluster, the majority now selects a new leader. When the old leader comes back, it discovers that a new leader is already elected with higher term, so the old leader steps down & become a
Follower.
Q. What happens when a cluster starts up?
A. All the nodes start up with random timeout, empty logs & begin counting down. The following figure explains it:

The black thick perimeter around the nodes represents time out. Note that the perimeter lengths are different representing different timeout values for each node.
Steps
- Each node is initialized with
term = 1. S4times out first.S4starts a new election process & increments local term’s value by 1.S4votes for itself & sends outRequestVotemessage to all other nodes in the cluster.
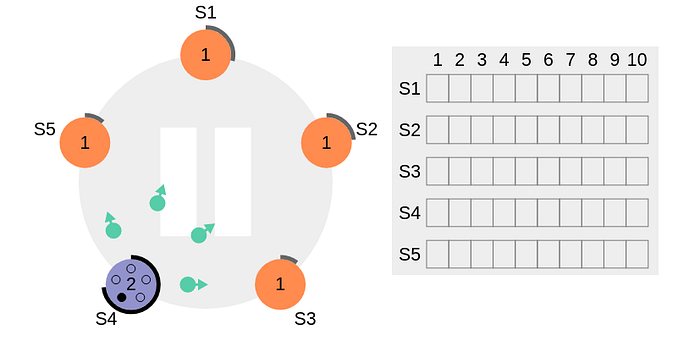
- All other nodes receive the request. They first reset their local term to
2since their current term is lesser & grants vote for the request. Their election timeout is now reset as shown below.
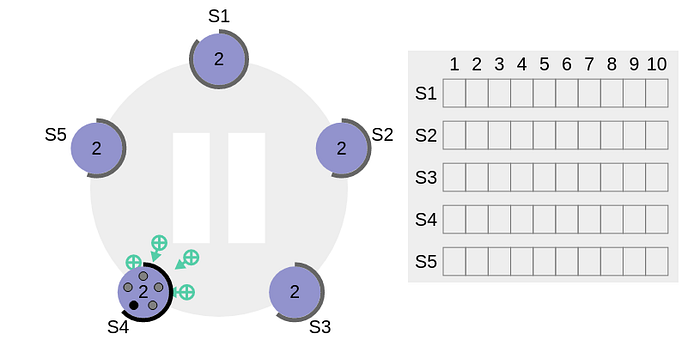
S4gets clear majority (+inside smaller green circle in the above diagram means affirmative incoming votes) & becomes the leader. The thick black perimeter aroundS4in the following figure indicates that it has become the leader of the cluster.
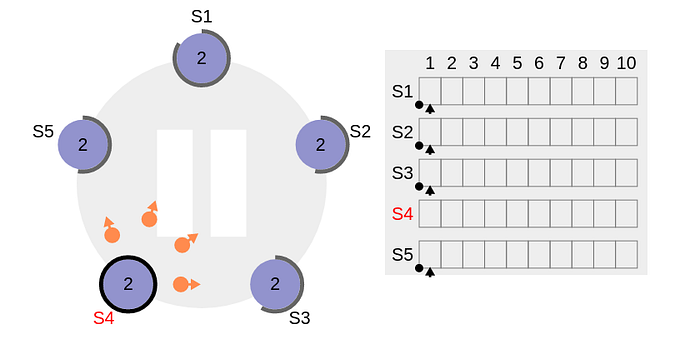
- Now
S4starts sendingAppendEntriesmessage to all other nodes. - There is something called Heartbeat Timeout as well which should be configurable in the system. The leader keeps sending empty
AppendEntriesmessages in intervals specified by the heartbeat interval indicating that it’s still alive so that the cluster does not unnecessarily initiate another leader election process. - Followers acknowledges each
AppendEntriesmessage.
Q. How many votes a node can give for a term?
A. Each node can vote only once per term.
Q. What happens if the leader behaves maliciously & does not send heartbeat?
A. No heartbeat possibly means that there is currently no leader in the cluster. If any leader intentionally stops sending heartbeat even though it’s alive, it triggers unnecessary leader election process & overloads the system.
Q. How do you choose the election timeout?
A. You should follow the following formula while choosing the election timeout:
Broadcast time << Election timeout << Minimum Time Between Failures (MTBF) of a nodewhere a << b means a is an order of magnitude less than b
Broadcast time: Average time for a node to send RPC & receive response in parallel from all nodes.
MTBF: Any node can fail for this or that reason. MTBF defines the minimum time between two such consecutive failure for a node.
Depending on the infrastructure, broadcast time can be from 0.5 ms to 20 ms. MTBF can be several months or more. You should choose election timeout which abides by this criteria. Anything between 10 ms to 500 ms should be good for election timeout. However, as mentioned earlier, 150 ms to 300 ms is ideal.
No Clear Majority Case
When multiple candidates time out at the same time, the situation becomes very in-deterministic. In the following diagram, nodes S1, S2, S4, S5 timeout almost at the same time & reach out to other nodes for votes. Now since 4 out of 5 nodes are competing for the leader position, no one would get majority as they have already voted for themselves in the new term.
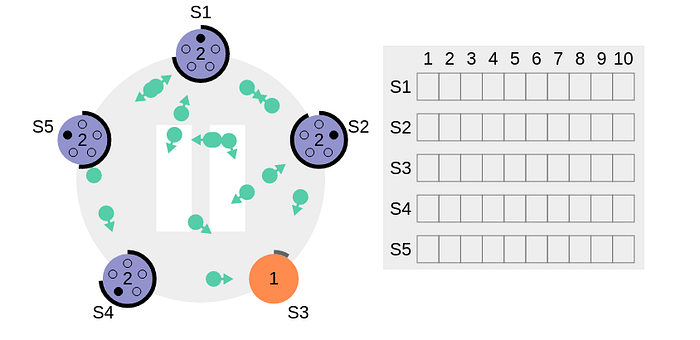
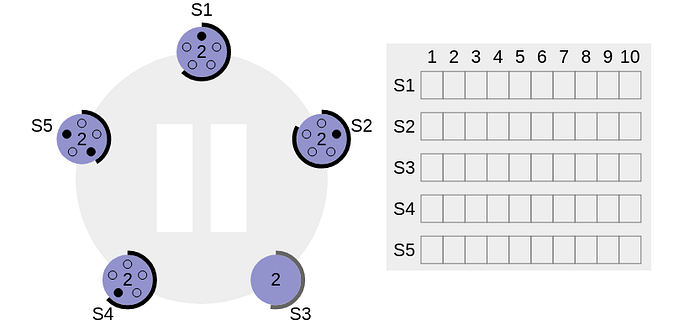
As it can be seen in the below diagram, S5 gets an extra vote from S3 & no one is the winner here. So all the nodes timeout & the same voting process starts again.
Quick Summary
- Raft helps to build a strongly consistent distributed system.
- Raft relies on Quorum concept to ensure consensus from the majority in a cluster.
- Odd count of nodes makes a better cluster than even count of nodes as it has more fault tolerance.
- Nodes can be in one of these three states at a time:
Leader,Follower&Candidate. - Raft is a leader oriented system. A leader must exist in the cluster before any operation can happen.
- Each node maintains its own state machine & log on disk.
- Committed logs are persistent & they eventually get replicated to all the nodes in the cluster.
- Logs always flow from the leader to the other nodes.
- Committed logs are finally applied in state machine.
- A term is a monotonically increasing counter which starts with a new leader election. Every node individually manages its own local term. Raft makes sure to eventually converge the term’s value to a single value across nodes.
- Raft uses RPC calls / messages for vote request & log replication purpose.
- Random election timeout generally helps to elect the leader with a trial or two, it prevents indefinite loop of voting process.
- When a cluster bootstraps, one of the node times out & asks others for votes. Upon granted vote by the majority, it becomes the leader.
- If no leader is elected, the election process is retried.
We have introduced ourselves to the basics of Raft & the very first leader election process. In the next part of this series, we’ll discuss Raft replication in details which is very critical to the protocol.
Stay tuned!

