Making sense of the RAFT Distributed Consensus Algorithm — Part 3

We discussed Raft replication in details in part 2 of this series. That becomes prerequisite for this article. Please head over to part 2 if you haven’t already.
We’ll simulate some scenarios in this article and see how Raft behaves in such cases. It’ll build a better understanding of the algorithms in your mind.
Case 1: Replicate a client command successfully with majority
Let’s see the happiest case first. It will help you to get a fair understanding of the life cycle of data replication process in Raft.
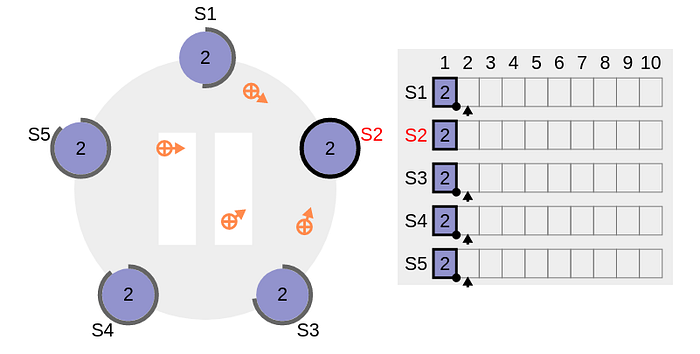
The leader node S2 gets a command from the client. It adds the entry to its own log at index 1( The logs in the following diagrams are 1-based ). The dotted line around the rectangle at position 1 in S2 bucket represents that the entry is uncommitted. The orange colour arrows indicate that the leader is sending AppendEntries RPC to the rest of the nodes with the intention to store the data in the majority of the nodes.

The starting index of the follower logs is also 1. All the followers receive the message, adds the log command to their individual logs, reset their election timer & acknowledges to the leader affirmatively.

At this point, leader & all the followers have added the command to their disk based persistent log.
Since all the followers responded positively, the leader got clear majority & commits the command to its local state machine. The solid black line around the rectangle in S2 bucket at index 1 in the following diagram indicates that the command is now is permanently committed by the leader. The leader can safely communicate to the client that the command has been written successfully in the system.
The followers have not committed the command yet since they are unaware of the leader’s commitment status.

In the next AppendEntries RPC, the followers get updated commit index from the leader & they commit too in their local state machines.

As seen in the above diagram, entries are committed in the followers now & they acknowledge back to the leader with success.
Let’s consider some failure scenarios in this process.
Case 2: Many followers crash together & no majority followers exists
- Before returning error to the client, the leader retries replication few times. Since it clearly does not get the majority in this case, there would be no change in
commitIndexof the leader. Hence no actual replication actually happens immediately. However, typically the leader holds the entry in its log, with future replication, this entry would get replicated. - This scenario is highly unlikely as we would like to place followers across multiple availability zone & unless our data centre or cloud provider badly screws up something, we won’t get into this situation.
Case 3: Before replicating to the majority, the leader crashes
With leader, the data may also get lost. Since data is not replicated to the majority, Raft does not give any guarantee on data retention.
Corner Case: Say the leader successfully replicated the log entry to the follower S1. The leader dies. Now in the absence of the leader, if S1 starts the leader election process & wins, since possibly it has more log than other followers, the log entries copied earlier won’t get lost.
Case 4: Leader crashes just before committing a command to the state machine
S1 is the leader which already replicated a log entry at index 1 to all the nodes in this diagram. However, S1 crashes before committing it to the local state machine.
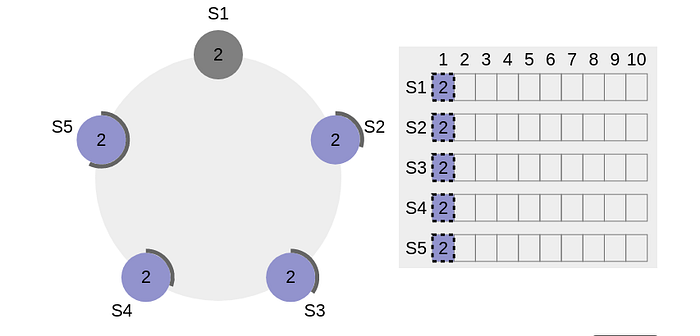
Next time when the election happens, any of the other nodes except S1 can become the leader. Since the entry is already replicated to the majority by S1 , it’s logically as good as a committed entry, by the rules of Request Vote process in Algorithm 4 described earlier, at least one node would be there which contains this entry & that would be elected as the new leader.
However, the new leader now won’t directly commit the log entry since after the new leader election, the entry belongs to a previous term — in the following figure, the new leader is elected with term 4 but the log entry belongs to the term 2 — all entries are surrounded by dotted rectangles meaning they are not committed yet.
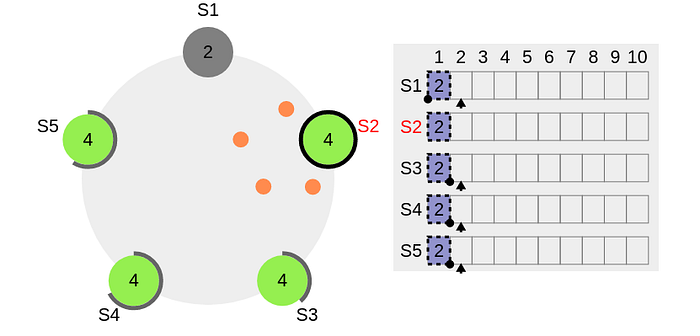
Remember, Raft never commits entries from previous terms directly even though the entry is there in majority nodes. Raft always commits entries from the current term by counting replicas as shown in Algorithm 1, from line 77 to 94. When entries from the current term are replicated, entries from previous terms indirectly get replicated as shown below:
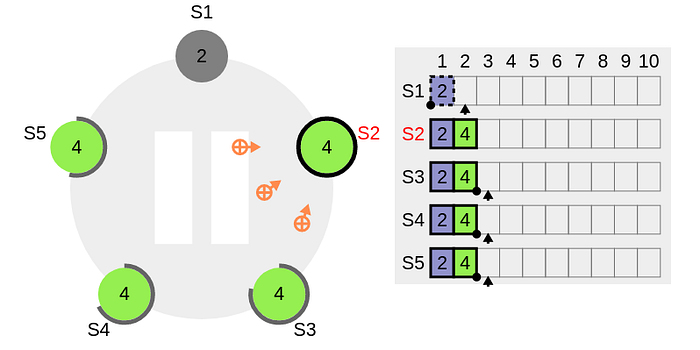
In the above figure, a new log entry gets added to the new leader S2 in term 4, when it gets committed, the previous entry with term 2 also gets committed. Both entries at index 1 & 2 are within solid rectangles indicating they are committed.
Case 5: Leader crashes after committing a command to itself but before sending commit request to the followers
This is also same as case 4. As long as a log entry is replicated to the majority of the nodes in the cluster, it does not really matter whether the leader crashes before or after committing the log to its state machine. The next leader would be elected from one of the majority nodes only since they have higher log index than non-majority nodes. So no data loss happens here.
Case 6: Leader crashes, comes back after sometime — the Split Vote Problem
If a leader suddenly disappears from the raft cluster ( but the client can still interact with it ) due to network partition or some error, a new leader would be potentially chosen by the majority. Ideally, all the new write operations have to be redirected to the new leader — this entirely depends on how you design the system to make the new leader discover-able by the client.
Q. How does a client discover the new leader?
A. There are 3 major options:
- Redirect the operation internally in the cluster: The write request can land on any node. If it lands on a follower node, it is redirected to the current leader by the follower; if it lands on the leader, the leader can serve it. However, to handle potential split-brain problem, before serving the request, the leader has to verify with other nodes in the cluster whether its leadership is still valid — it requires some extra check / RPC call resulting into higher write latency, but the client remains light since it does not need to bother who the current leader is.
- Cluster-aware client: The client always gets update from the cluster about the current state. May be with a very short interval of heartbeat, the client keeps on updating the cluster state in its record & verifies existence of the current leader all the time by confirming with the majority nodes. The client becomes heavy in this case.
- Manage a central registry or configuration store: You can manage a central registry which would be always updated with the current leader & other metadata of the cluster. Every time a new leader is elected, the configuration gets updated. So clients can contact the configuration store first to find the current leader & then sends a read / write request to the leader. However, the configuration store becomes a single point of failure now.
Q. What happens if a write operation is still received by the old leader?
A. The situation ideally should be rare. However, if it happens in some edge case, the data might get lost if it gets accepted by the old leader. Before accepting a write the leader can contact other nodes to validate whether it’s still a valid leader, however it makes the write operation very heavy but it prevents data loss since on error, the client can re-try the operation and the new request may land on the correct leader or valid cluster node.
Case 7: A follower has more logs than the current leader
As stated earlier, follower logs can be overridden. In case a follower gets some extra log probably from an earlier leader but the logs don’t exist in majority node, Raft can safely override them.
Configuring Read & Write path in Raft
- A write operation has to always go through the leader.
- A read path can be configured based on the system’s read consistency guarantee, couple of options:
i. Only the leader can serve the read request — it checks the result of the client query in its local state machine & answers accordingly. Since the leader handles all the write operation, this read is strongly consistent read.
ii. Any node can serve read- it means faster read but possibly stale at times. Any node disconnected from the cluster due to network partition can potentially serve the client query & the result might be stale.
Q. What happens to the cluster when for some reason the quorum is lost?
A. If majority nodes are down, write operation certainly stops. However, if you have configured the read to be served by any node, then read operations can carry on although data might be potentially stale as described above. It depends on your business use case what kind of read operation is good for your system, accordingly you can tune the configurations.
Raft Usage In Real Life
There are several popular products which are using Raft internally for consensus:
- Distributed relational data stores like Google Spanner, YugaByte need consensus for leader election, distributed transaction & data replication. These are strongly consistent system. Spanner uses Paxos whereas YugaByte uses Raft for leader election & data replication purpose.
- etcd is a strongly consistent distributed key value store. It uses Raft internally to gain consensus while writing data.
- Kubernetes internally uses etcd to store cluster configuration. So Kubernetes indirectly depends on Raft as well.
- Docker swarm, a competitor of Kubernetes also relies on Raft.
- Service discovery system like Consul uses Raft to store service configuration information.
- Kafka is no longer using Zookeeper to store the cluster metadata, it now has its own implementation which internally uses Raft to get consensus on the metadata.
You can find more implementations here.
Raft Performance
Raft is very heavy especially in the write path, it’s mostly used for a strongly consistent system. Depending on how you design the system, the read path can have tune-able consistency. If you need strongly consistent read, read path becomes heavy as well. Node placement ( whether nodes are in the same region or different ) impacts the performance heavily. May be a system with Raft won’t be able to scale to a million requests per second, but should be good with few tens of thousands — if you ever need to design such system, execute a custom benchmark which satisfies your requirement.
However, Raft does not restrict you from applying any optimization to the algorithms. There are some implementations which have already optimized Raft to gain more performance.
Performance is the reason why most of the real life Raft use cases are about leader election, replicating configuration changes, cluster membership changes etc — these events don’t typically very frequently in a cluster.
Quick Summary
- If a log entry is not replicated to the majority by the leader, there is a chance of data loss.
- If a log entry is replicated to the majority by the leader, but not yet committed or applied to the state machine & the leader crashes, that’s okay, since one of the majority nodes becomes the new leader which already has the entry in its log & it replicates the entry indirectly while committing data for the current term.
- Follower logs can be overridden but not the leader’s log.
- Logs across all the nodes are exactly same & consistent.
- While electing a leader, Raft does not give any guarantee that a node with longer log would win. First terms of last log entry between a peer & the candidate is compared. If the terms are same then only log length is compared.
- Raft could be slow in performance.
Conclusion
Raft is designed to be understandable but it’s still so complex, there are so many cases to consider. You have to go through the Raft paper couple of times to make an understandable image in your mind. So this series of articles uses a lot of simulation for different use cases & also explains the code in detail. I hope this article helps you a lot in understanding the core algorithm.
The beauty of these kind of algorithms is: irrespective of how many articles you read or videos you watch, you still need to think critically about it & different possible edge cases. I would still suggest to go through the paper once although this series is very elaborate. Spend few days, you would slowly start understanding it.
In case you have any feedback to share or the article has some unintentional mistake or lacking some information, please put a comment.
Some Good talks on Raft to watch patiently
Reference
- https://raft.github.io/raft.pdf
- https://blog.yugabyte.com/how-does-consensus-based-replication-work-in-distributed-databases/
- https://eli.thegreenplace.net/2020/implementing-raft-part-0-introduction/
- https://blog.containership.io/etcd/
- https://docs.docker.com/engine/swarm/raft/
- https://www.confluent.io/blog/removing-zookeeper-dependency-in-kafka/
- Simulation: https://raft.github.io/raftscope/index.html, on git: https://github.com/ongardie/raftscope
- https://www.consul.io/docs/architecture/consensus

