Optimize your repository using Git GC

Hello Techies 👨🏻💻
Once again, I’ve come up with an interesting topic i.e how git optimizes its repository. If you want to understand this concept better then read through the article!
Today’s Inspiration: “Little things make a big difference.”
So let’s get started… 😃
Before we deep dive into the working of GC. Let’s understand why we need garbage collection in git. As some of you may know, the concept of garbage collection is originated in High-Level Programming Languages i.e C, Java, and C++ because of memory management.
In the Java programming language, dynamic memory allocation of objects is achieved using the new operator. Once an object is created, it uses some memory and the memory remains allocated until there are references for the use of the object. When there are no references for an object, it is assumed to be no longer needed and the memory occupied by the object can be reclaimed. There is no explicit need to destroy an object as java handles the de-allocation automatically. But in case of C++, you have to do manually de-allocation of objects.
The same thing happens in git as well. It reduces the disk size by cleaning up unnecessary objects. An object (blobs, trees, and commits) with SHA say — b15cae53e0f642d6804f060c02a83dbc3a1fb7ca will be stored at .git/objects/b1/5cae53e0f642d6804f060c02a83dbc3a1fb7ca (the split in first two characters to improve performance of the file system as now not all objects are stored in the same directory). Objects stored as above are referred to as Loose objects. The Loose object is simply a compressed data stored in a single file on disk. Every object is written to a separate file.
Git is a content-addressable file system i.e. it takes an object and stores it in files addressable by hashes. If you’re not aware of these objects then I will highly recommend you to go through this link.
Let me give you some basic introduction of objects:
- A “blob” is used to store file data- it is generally a file.
- A “tree” is basically like a directory- it references a bunch of other trees and blobs (i.e. files and sub-directories).
- A “commit” object holds metadata for each change introduced in the repository, including the author, committer, commit-data, and log- messages.
The git gc command cleans up unnecessary files and optimizes the local repository. GitHub runs this operation on its hosted repositories automatically on a regular basis based on a variety of triggers. Locally you can run it at any time. Running it won't have any adverse effect on your repository.
Lately, I have been using GitHub and I’m wondering, What is the repository limit for files hosted on github.com. I’ve been wondering this because I was thinking of using GitLab since it allows 10GB for each repository.
As of December 2019, the GitHub docs say: We recommend repositories be kept under 1GB each. Repositories have a hard limit(Maximum Value) of 100GB. If you reach 75GB you’ll receive a warning from git in your terminal when you push. This limit is easy to stay within if large files are kept out of the repository. If your repository exceeds 1GB, you might receive a polite email from GitHub support requesting that you reduce the size of the repository to bring it down back.
If you own the repo, you can find the exact size by opening your Account Settings > Repositories (https://github.com/settings/repositories), and the repo size is displayed next to its designation.

In my case, the size is only in KB but when you work on actual real-world projects the size may be in MB or GB. So, we have to maintain our repository size using git gc command by removing unreachable objects.
When you start up with your repo, you mostly have loose objects. As the number goes high, it becomes inefficient and they are stored in a pack file. Such objects are called packed objects.
Now, Let’s see the working of GC with an example:
Let’s initialize a new repository called “gc_example” with git init.

Let’s make a commit in this new repo.
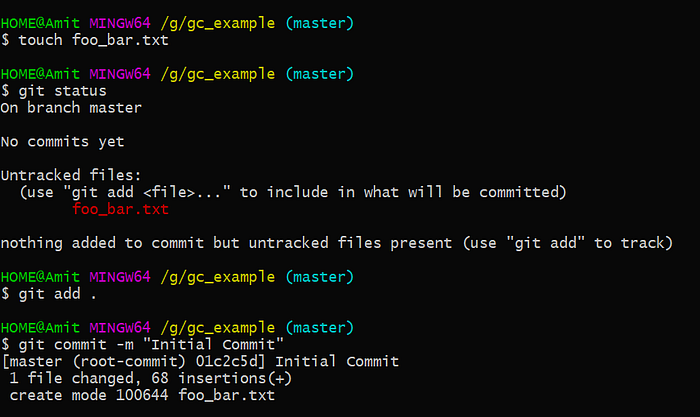
Let’s see how many objects do we have into this in .git/objects folder by using the command find .git/objects -type f .
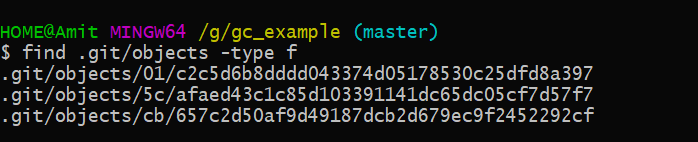
What we can see now is that we have 3 objects and the SHA-1 of the object. We can also check the type of the object and the contents of the objects using git cat-file command.
These three objects are of different types are blobs, tree, and commit. Let’s view one by one.
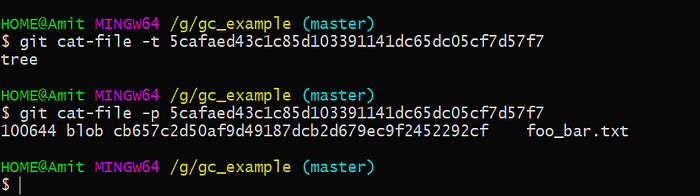
This object is a type of commit.
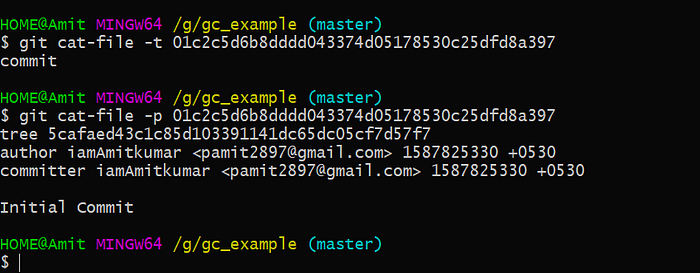
This object is a type of blob by using -p option you can see the contents of a file.
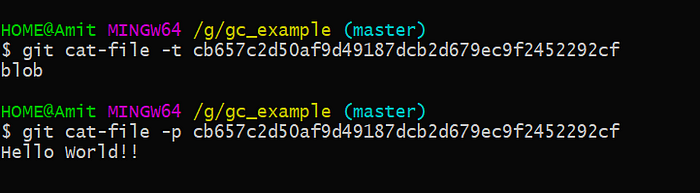
The blob gives us the content of the file but it doesn’t tell us the source of the content so here comes the tree object which gives information about the name of the file and contains the reference of a blob object.
Here, we have all the information that we need now and everything is nice and clean but one downside of this approach is that if we try to do small changes into this foo_bar.txt file and we’ll recommit again we will see that git creates as a new completely blob file that contains the whole foo_bar.txt file generating basically our duplicates of the file every time that we commit and to show you this problem I created another proposal that is exactly like this one so it’s a brand new proposal with my single file but the file instead of containing just “hello world” contains more than 10k line of code so it’s a really big repository.
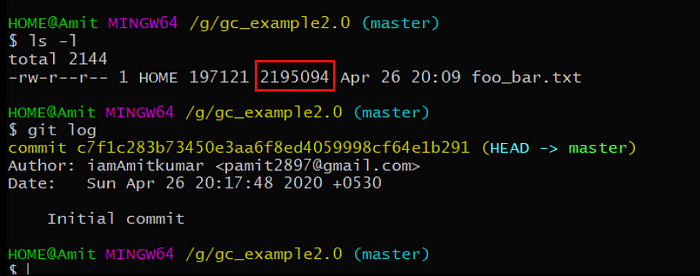
I’m inside this new repository and so you can see that we have only one file and this file is too big containing 2.1M of data and also we have only one commit.
ls -l: Lists more information about all the files/folders in the current directory, one file/folder per line.
We can see the list of objects inside this repository with a little bit more detail than what we did before with a different command that is git cat-file and then two options [ — batch-check] and [ — batch-all-objects].
If --batch or --batch-check is given, cat-file will read objects from stdin(Is an input stream where data is sent to and read by a program), one per line, and print information about them.

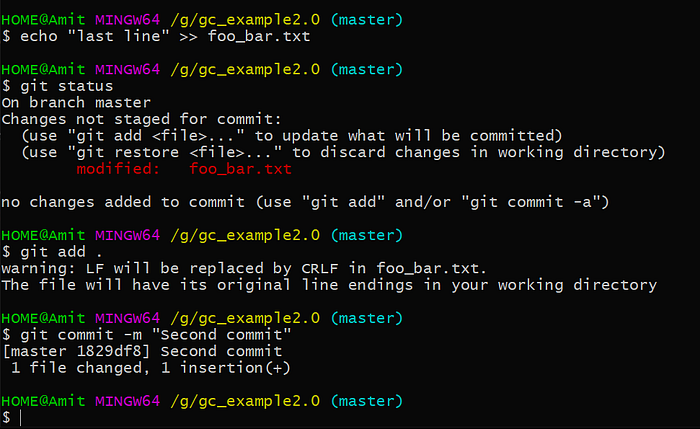
Here we have a list of objects with the left the SHA-1 of the object than on the right we have the type of the object and the size this object takes on the disk. Now, I will try to append one line to this file and recommit again and we can see how many objects are then created.
Let’s print again the list of objects.
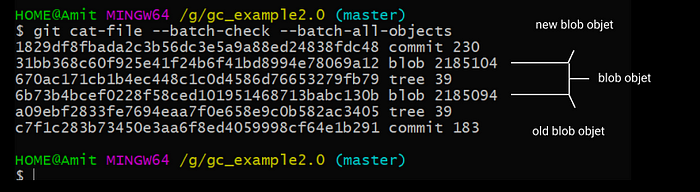
Now, we have now six objects that is what we expect but the bad thing is that we have a two blob object that contains a basically a duplicate of the file and each of this object takes 2.1M of data.
Now, I will show you how we can reduce the size of these two objects take. We can finally try to reduce the size of this repository, reducing the size of the repository is done by a common little it’s called git gc this stands for git garbage collection and this process usually automatically launches it from git. whenever you push your repository to live remote or when you really a lot of object into your repository this can vary depends on your configuration or the tools that you are using so we will see now how we can execute this garbage collection manually, to execute the garbage collection we just need to run the git gc command and we can pass the parameter to this command this is --aggressive that means that this command should be a little more aggressive on saving space instead of saving a CPU.
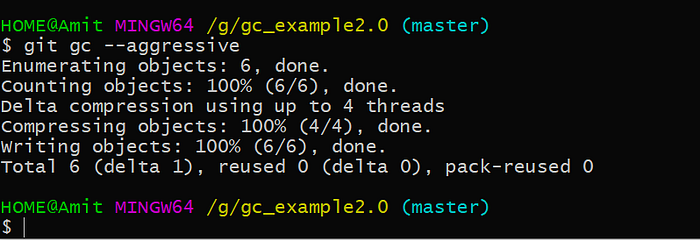
We expect now to have a less object or at least less space into this repository. Let’s re-execute the command git cat-file --batch-check --batch-all-objects to list all the objects. This command tells us that we have still six objects after performing a git gc operation.

But, what this command that doesn’t tell is that those objects are not stored into the objects file like it was at the beginning of this blog and we can see this checking directly into the file system.
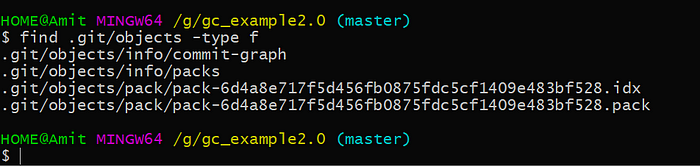
As you see, there is no more objects file. Instead there one pack and index file and this pack file it’s a binary object that contains inside all the objects that we had before but in a more efficient way also we have the .idx file that is the index because the pack is a binary file so we need to keep track of the offset where all the information is stored and all this offset is stored into this .idx file. If we look into this file we should be able to see our older objects. So there is one command in git called git verify-pack -v pack_file_path which shows you the content of the pack file. The -v option is called verbose.
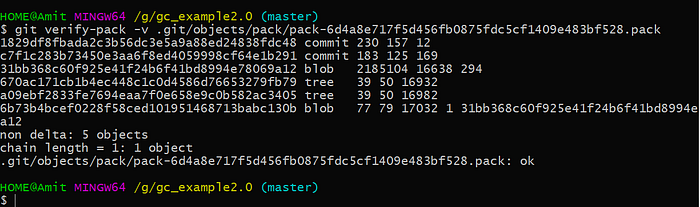
As we expect that this pack file contains a six object containing two commits, tree, and blobs but what is really interesting is that the two blobs are not occupying the same space on disk the blob 31bb368 SHA1 here occupies 2.1M while the 6b73b4b SHA1 occupies only 77. Why is this? It’s because the blob 6b73b4b here contains now only the difference does not contain the whole file and even better we can see this blob 31bb368 here is exactly the same SHA1 of the object that we store before. So we know this one is the object with the additional line so is the latest object while this one 6b73b4b is the oldest object.
We can also understand how git stores information into the pack file because this blob 31bb368 here is the most recent subversion of the file so we know that’s the inside of the pack file. The older blob 6b73b4b only contains the difference of the foo_bar.txt file. While for all the previous commit git stores all the difference into a blob that contains again the difference and a reference to the newest version of the file. We were able to reduce the size of the repository by almost 50%.
Conclusion
Users are encouraged to run this task on a regular basis within each repository to maintain good disk utilization and good operating performance.
Hope you will like this! Thank you & Keep Learning :)

