Scaling cryptocurrencies: DAGs
Disclaimer: This information is based on my own research and I make no guarantees about the correctness or fit for any particular use. Let me know in the comments if you have something constructive to add, but don’t freak out, OK?😉
The goal of bringing basic, decentralised payments to the masses remains outstanding due to Hard scaling problems. These problems are rooted in the mechanics of consensus algorithms and fundamental limits in our ability to shuttle data around a global network.
Visa is frequently referenced as the “gold standard” in scalability discussions for cryptocurrencies. The Visa network processes 150 million transactions per day — the best blockchains process around 1.5 million transactions per day.
The fundamental limit for every blockchain is:
TPS = Transactions per block / seconds per block
Increasing the transactions per block or producing more blocks makes it harder for the network to share all the relevant data globally. We must always tradeoff throughput against reliability.
Today I’m going to briefly discuss DAGs — their promises, limits and outstanding challenges.
Directed Acyclic Graphs (DAGs)
Directed Acyclic Graphs (DAGs) sound more complicated than they are. A DAG is any set of items that can each reference other items in the set, but never in a circular way (not even indirectly).


Notable examples of coins based on this structure include:
- IOTA
- Byteball
- DAGcoin
- Hashgraph
A blockchain is technically a DAG too, with the added restriction that there is a strict linear ordering of all items in a sequence. The main argument for DAGs is that the strict sequencing in a blockchain directly causes or exacerbates the worst scaling issues we are seeing today.
Because the structure of a DAGs isn’t as strict as a blockchain, the items can be shared and processed individually in a messier, out of order fashion. The less strictly ordered, realtime, global co-ordination that we require, the easier it is to scale up the network. DAGs are an elegant generalisation of blockchains, for the most part.
DAG projects are very new, no more than a year in production vs. bitcoin’s (almost) decade of real world usage. They certainly show promise in terms of beating blockchains at “on-chain” scaling — whether they meet or exceed the needs of a global economy outside the lab remains to be seen.
IOTA has produced over 1000 tps on their testnet (lab conditions) while Byteball has achieved around 20 tps on the mainnet during stress tests with little or no efforts (so far) to optimise any code for high load (there is low hanging fruit there). DAGcoin simply claims “Everybody in the world can make a transaction at the same time”. It is encouraging to see that the lower bounds of immature DAG projects are on par or exceed the upper limits of most blockchains.
While DAGs claim to solve the block problem, they still rely on redundantly sharing and processing data between every full node on the network. The increased tps may simply shift the pain towards drastically increased storage and bandwidth requirements for the poor full-wallet users 😞. Byteball is already in double digit GBs for data storage. In a future post I will discuss projects attempting to avoid this problem by splitting rather than duplicating validation and storage needs.
Avoiding double spends without blocks is hard
A raw DAG structure cannot detect malicious double spends. Transactions can be guaranteed to come after their parents, but the order between two transactions that are siblings (or descended from siblings) is undefined. This is super important because the only way to resolve a double spend is to decide which transaction came first!
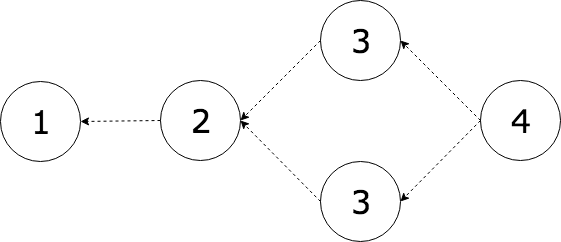
This ambiguity increases as you add more and more branching items to the DAG. To make things worse, anyone can deliberately hide a branch from the network (including some double spends) then broadcast it later as part of an attack. If that branch is given priority over honest transactions by the network, fake transactions will be honoured over honest ones.
To avoid fake branches/items, current strategies invoke “witnesses”. A witness creates items that can be used as clear reference posts. For each item posted by a witness, we can unambiguously say that every other item either comes before or after that point. This doesn’t perfectly order every individual item but it does give us incremental “checkpoints” to protect against hidden branches. The checkpoint functions similarly to a block in a blockchain but:
- has no fixed size
- no fixed schedule
- doesn’t require the witness to be aware of any items other than those at the end of each branch (provided we can delegate pre-validating the rest of the branch)
- new items aren’t floating in a “mempool” backlog, they are continuously self-organising into pre-validated branches to be included in an upcoming checkpoint
These differences between witnessing and block producing provide the additional flexibility in how DAG networks can operate.
Because no branch or item is confirmed until a witness has seen it, hidden branches cannot reverse already-seen items.
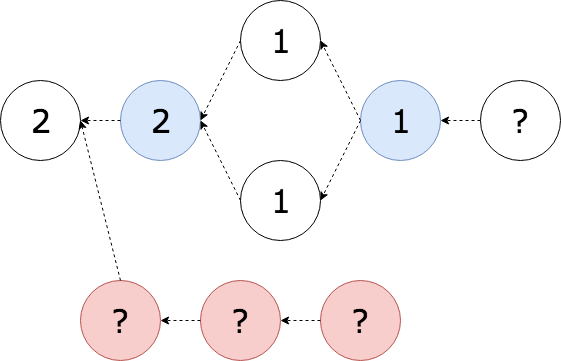
There are a few things to note at this point:
- As there are no “blocks” the blockchain scaling equation doesn’t strictly apply (there are network limits, but we have more wiggle room)
- Without blocks with size limits, any item can hold any amount of data
- We still cannot differentiate between siblings within a witness level, so we need a fair tie breaker rule (e.g. lowest hash wins)
- Without witnesses we must prove a negative (impossible) “no attacker is hiding a branch” but with them we can simply show “my transaction has been seen”
- Items that haven’t yet been seen by a witness have no order and are not confirmed, but can be pre-validated and included in new branches immediately (no amorphous mempool)
- We rely on witnesses to not collude with an attacker to award a malicious branch a high “seen” score
- Choosing different items to witness a DAG reorders the DAG — the choice of witness defines the order of a DAG, in a sense the witnesses items define time in the DAG
In real-world systems we cannot simply rely on one witness (total centralisation). We cannot randomly assign witnesses because an attacker can create millions of fake accounts to outnumber honest accounts, then very quickly take control (sybil attack).
Appropriate witness selection is A Big Deal if DAGs are to scale and remain decentralised.
Current DAG based systems use both centralisation and groups of witnesses collaborating to produce each checkpoint (e.g. voting).
Summary
DAGs have some nice properties that seem to make them more scalable than blockchains. There are no blocks to fill or schedule, and witnesses can process less data than block producers giving us more leeway in the messy real world.
DAGs need witnesses to checkpoint data periodically so we can avoid double spends, similar to block producers, but scaling witnesses is theoretically far easier than scaling block production.
Whoever controls the witnesses controls the network. No transaction is valid until the witness(es) “see” it, so decentralisation of witnesses is critical to the long-term viability of any DAG network.
I haven’t seen compelling decentralisation in the DAG space so far, only some vague promises that are yet to be delivered (hashgraph is patented so by definition not decentralised). This alone makes me skeptical whether the current breed of DAGs will outcompete existing blockchain networks, despite apparent advantages on paper.
DAGs still rely on a shared ledger of data that must be redundantly streamed, processed and stored globally in near real time by many “someones”, even if not by the witnesses themselves. Whether this limit is academic or crippling once block production is removed remains to be seen.

