What Makes Apache Druid Great for Realtime Analytics?
Apache druid is one of the most popular open-source solutions for Online Analytical Processing (OLAP). It’s used by many tech companies such as Airbnb and Netflix to run queries on streams of data comprising millions of events per minute. It allows companies to make decisions in near real-time.
The main selling point of druid is it easily scales to a million RPM of writes and beyond with sub-second latencies and is highly available during the whole operation. But a lot of databases these days have high availability and sub-second latencies, so what makes druid any different?
Relational and Key/Value Stores vs Druid

Relational databases such as MySQL are good at processing transactional workload which generally has row level queries. For analytics, you need to get aggregates on some columns which requires scanning a lot of rows across multiple shards. RDBMS can’t do that efficiently enough to enable data exploration in real-time.
As far as NoSQL Key-Value Databases are concerned, the aggregation calculations will certainly be inefficient as you need to query multiple partitions across a number of nodes. You can get around this by pre-computing the data at some granularity (such as 1 min.) and store it against a key. By following this approach, however, you lose the ability to do exploration on multiple windows. Storing aggregates for all possible column combinations is also not feasible as it leads to exponentially increasing storage requirements.
Druid has been designed to solve these problems i.e. enable exploration of realtime data and historical data while providing low latencies and high availability.
How does it work?
Druid consists of multiple nodes each of which play a different role. These all nodes work in harmony with each other (mostly using Apache Zookeeper for coordination) to deliver the performance.

Let’s talk about each of these nodes in more detail. If you are already familiar with the nodes and their interaction, you can directly skip to the last section.
Realtime (Middle Managers)
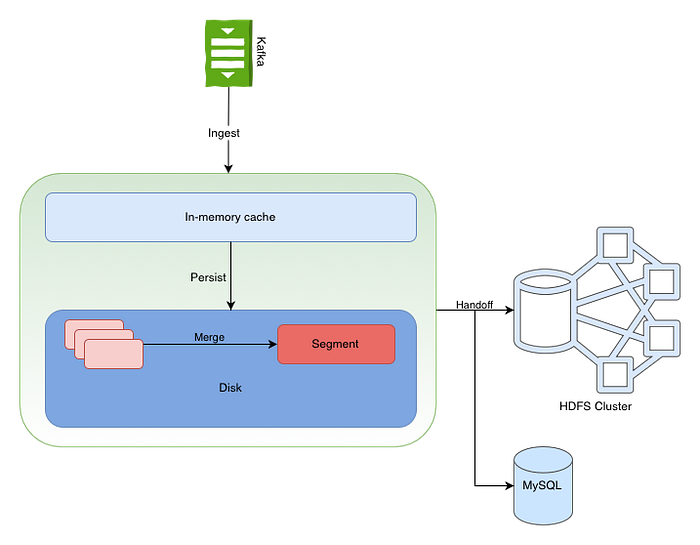
These nodes are responsible for handling real-time data both for read and writes. The writes particularly consists of the 4 main steps:
- Ingest- When a data is written in druid, it first goes to the in-memory index buffer of this node. This buffer is heap based and events are stores in row wise fashion.
- Persist- To avoid heap overflow, this index is periodically persisted to disk for durability. The in-memory buffer is converted to a column oriented storage format and made immutable. The persisted index is then loaded in the off-heap memory for faster queries.
- Merge- A periodic background task merges the immutable blocks into what is known as a segment.
- Handoff- The segments are finally uploaded to distributed data stores (referred to as deep storage) such as HDFS for greater durability and availability. It also updates the segment’s metadata in MySQL for other nodes to see.
Historical
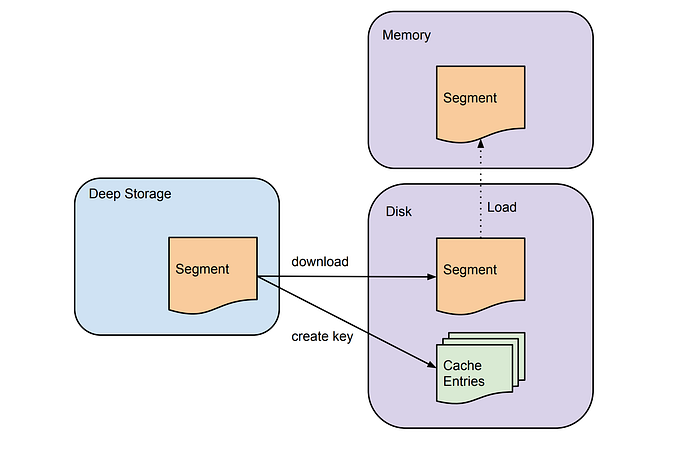
These nodes load segments from deep storage and then serve the queries on top of it. Most of the analytical queries which run on druid will most of the time go to these nodes. Hence, these nodes are the main workers of the clusters.
The nodes obtain information of any new segments publishes in deep store from zookeeper. The segment is then downloaded and loaded for serving. The nodes also cache some segments in the local disk which allows them to quickly serve queries in case some restart happens. The nodes also offer read consistency since they are only dealing with immutable segments.
Historical nodes can also be divided into multiple tiers each with different configurable. e.g. Nodes with higher cores can be put in a tier to serve frequently accessed data and the ones with lower resources for the rest of your data.
The availability of zookeepers hinders the ability of these nodes to load new segments but old segments keep on getting served without any downtime.
Brokers
All the user queries go to the broker nodes. These nodes then redirect the requests to appropriate historical and realtime nodes, merges both the results and send them back. The nodes also maintain an in-memory LRU cache (which can be changed to use Memcached). The cache contain results on a per-segment basis. However, the results only for historical node segments are caches since real-time data will keep changes quite often.
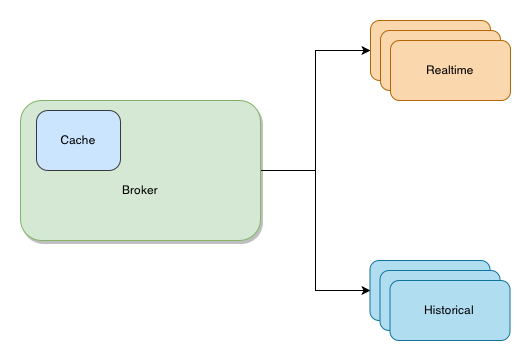
These nodes also use zookeeper to discover other nodes. In case of zookeeper outage, they serve data assuming the last snapshot of the cluster state.
Coordinator
Since Historical nodes are dumb, it’s the responsibility of the coordinator to tell them what to do. Specifically the coordinator issues the following commands:
- Load new segments published by realtime nodes in HDFS.
- Drop outdated data.
- Replicate data for redundancy so that you can tolerate node failures.
- Load-balance data across multiple nodes.
Only one coordinator node is elected as the leader and it’s responsible for the whole operation while rest of the nodes only act as a backup.
The coordinator fetches the latest cluster state from the Zookeeper and information about the segments which should be served from MySQL. The outage of MySQL as well as the zookeeper hinder the ability to assign or delete new segments but the old segments are still queryable.
So what makes it better than peers?
Separation of responsibilities
Since each node is concerned with only one major concern, it simplifies the complexity of the overall system. All the components have minimal interaction with each other and intra-cluster communication failures have almost no impact on availability (during read). The cluster is kept in sync through zookeeper. Even if the zookeeper is down, though you won’t be able to create any new segments thus affecting writes but reads can still happen.
Column oriented storage
Since druid is designed for analytical queries, it stores the data in column orientated format. Column orientated format allows for better compression ratios (since most of the data in a single column is similar) and also better query performance because generally not all columns are accessed in an analytics query so only the data actually needed is loaded. For string columns, druid generally performs dictionary-encoding and then apply LZF compression to reduce the data size.
Preventing unnecessary scans
Druid maintains an inverted index of string values so that we can know in which rows a particular value is seen. This allows to scan only those rows in which a value is present.

The inverted index of above table will look like
Foo : [1,0,0,1,0,1]
Bar : [0,1,1,0,1,0]
where 1 represent that the particular key is present in the row at the index. If you want to scan all the rows containing Foo and Bar simply take the OR of both indexes.
Cardinality estimation
To get accurate cardinality aggregations such as determining number of unique users visiting your site every minute, you will need to store the users in some sort of data structure (such as a HashSet) and then take the total count of the elements in it. However, this leads to a lot of space requirement.
Druid on the other hand, performance it using HyperLogLog, which gives approximately 97% accuracy. This is generally fine for most of the people running analytics query. You can even make it faster by pre-computing the HLL at ingestion time during indexing.
Pre-aggregation
Druid can pre-aggregate data at ingestion time (known as Rollup). This reduces the size of the stored data and also makes aggregation queries much faster. You do lose per row information in this case that’s why it can be disabled during ingestion.
Caching
Druid maintains a per-segment query cache on the brokers which helps in quickly returning the results. It also caches data in historical and real-time servers for faster scans.

Load balancing
The coordinator distributes the segments in such a way that it is not skewed among historical nodes. It takes into account data size, source and recency so that it also provides maximum performance e.g. normal queries cover a single data source spanning across recently created segments so it’s wise to replicate recently created segments at a higher rate so that those queries can be served by multiple nodes.
Time based partitioning
Druid requires a mandatory timestamp column for data distribution and retention. The data containing timestamps spread over a year is better partitioned by day and a data with timestamps spread over a day is better partitioned by hour. This timestamp is also used to ignore old events while writing to druid. Partitioning by time also helps in distributing and replicating the segments better.
If you want to explore more about Druid you can refer to the links below:
Connect with me on LinkedIn or Twitter or drop a mail to kharekartik@gmail.com
