How System Clocks Can Cause Mysterious Faults?

Clocks are used in applications for a variety of purposes such as figuring out if your request has timed out yet or measuring the latency or just for tracking the events.
For most of these tasks, people use system clocks. This is fine in a single machine environment where everything is under your control (although, I highly doubt it!!). In distributed systems, however, things can go out of hand without even you realising it.
Let’s take a look at what problems you may need to deal with.
What can go wrong?
Time travel
The usual clock which your system uses is called time-of-day clock. e.g. System.currentTimeMillis() in Java is time-of-day clock. These clocks return the number of epochs passed since 1st Jan 1970 12:00 AM UTC. Commonly people rely on this particular implementation.
The issue is these clocks are kept in sync through a mechanism called NTP (Network Time Protocol). NTP servers determine the accurate time through GPS receivers or other sources and then adjust the systems’ clock. This sometimes makes the clock go forward (if it’s running slower) or backward (if it’s running faster) in time.
So, you might send a request at 10th second of a minute from server 1 and might receive the response on 9th second of the same minute. Thus, your latency measured will be negative, which doesn’t make any sense.

To counter this issue, you can use monotonic clocks. These clocks always move forward in time (hence, the name monotonic). The difference between the timestamps returned by these clocks can be used to measure latency/elapsed time. However, the absolute timestamp is meaningless. e.g. in Java, System.nanoTime() is a monotonic clock, which returns number of epochs from some arbitrary timestamp which can even point to future.
Monotonic clocks are also not completely safe. NTP servers can speed up or slow down the clocks (known as slewing) by around 0.05% but they cannot cause the clock to jump forward or backwards.
What time is it exactly?
The clocks on normal computers drifts from usual frequency. This drift depends on weather/location etc. According to google, there is a 6ms drift in a clock which is synchronised every 30s or a 17s drift in clock being synchronised once a day which is a lot for micro-services with sub-second latencies.
The NTP sync is also limited by the network delay. Generally there is a minimum error of 35ms though latency spikes can lead to more delays. In public internet connection, It can even lead to delays of more than 100ms to 1 second.

In Virtual machines the hardware clock is also virtualised. Thus there can be a scenario where a VM is paused by hypervisor for tens of milliseconds. Any application running in this VM will see time jump forward in an instant.
1 minute != 60 seconds
Leap seconds lead to a minute with 59 or 61 seconds and that can mess up the systems quite easily. In fact it led to crash of major websites such as LinkedIn and Reddit in around 2012 and failed the Cloudfare’s DNS in 2017.
The issue in Cloudfare was the assumption in code that time cannot go back. When the leap second was adjusted, the system clock went back a second. This led to a difference between current timestamp and previous timestamp as negative. The program failed when this negative number was passed as an upper limit to unsigned random integer generator function (rand.Int63n(n)).
Google deals with such errors by performing the leap second adjustment gradually over the course of a day through modifications in NTP.
How to deal with these issues?
So now that we agree that clocks can lead to a variety of problem, let’s focus on what has the community done to deal with it.
Don’t use system clocks
If databases use system clocks for ordering the events that can lead to multiple problems. One example would be the Last write wins (LWW) strategy in NoSQL DBs such as Cassandra e.g. If one node in DB is forward in time than another node, then even though the second node may do the last update, the write from the first one may win and the second one discarded.
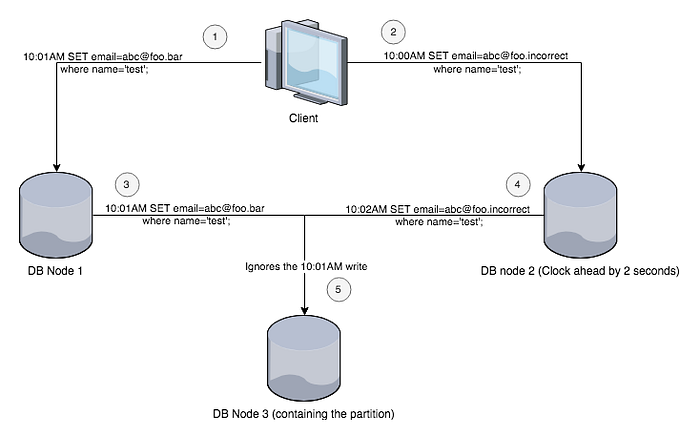
To deal with this some DBs use logical clocks (sometimes known as vector clocks) which are based on incrementing counters rather than number of epochs elapsed from a particular time. This helps in accurately determining what occured before and what later.
Use system clocks but check for error
Rather than returning the exact timestamp, systems can return an interval in which the timestamp can lie. This range can be calculated either by measuring the error of the system clocks with GPS or by using the measurement’s provided by the manufacturer itself.
This is what Google’s TrueTime API does. It returns an interval [earliest, latest] in which the timestamp can lie. This API is utilised by Google in their Globally distributed ACID database, Spanner. For the purpose of supporting transactions, Spanner used snapshot isolation. Generating incremental counters across a globally distributed system is difficult so spanner uses timestamps to determine what happened later.
If you have two intervals A [A(start), A(end)] and B [B(start), B(end)] , B would have definitely occurred after A if A(end) < B(start). If there is any overlap, you can’t be sure. To deal with this spanner deliberately waits for the period of interval before committing a transaction. This ensures that any later transactions occur at a time that intervals don’t overlap. To keep this wait time in check, Google deploys GPS receiver or atomic clocks in each datacenter to sync clocks within 7ms.
Use an accurate clock
HFT (High Frequency Trading) systems use very accurate clocks. This accuracy is achieved by using GPS receivers, the Precision Time Protocol (PTP) and careful monitoring. However, this requires a lot of effort, expertise and expense and still there are plenty of ways in which the clock sync can go wrong.
Drifts in clocks are hard to detect since they don’t lead to any immediate failure in most of the cases. Ignoring these simple faults have led to many failures in production systems, the stories of which can be found in abundance.
If you want to read more on this topic, you can refer
Connect with me on LinkedIn or Twitter or drop a mail to kharekartik@gmail.com

